
Automatisation du cycle de vie des applications : du développement au déploiement


La mise en place progressive de méthodes d’automatisation a permis d’automatiser complètement le cycle de vie des applications, depuis le développement jusqu’au déploiement. Nous verrons dans cet article les changements que cela implique, et quels sont les avantages que l’on a à automatiser l’ensemble du cycle.
Avec l’arrivée des méthodes agiles et le raccourcissement des délais entre les livraisons applicatives, les équipes de développement ont commencé à automatiser le cycle de vie des applications en mettant en place l’intégration continue.
Le principe est le suivant : le développeur soumet son code de façon très régulière dans un système de gestion de version. Chaque soumission déclenche la compilation du code, différents types de tests et la génération d’un artefact applicatif : le package qui pourra ensuite être déployé.
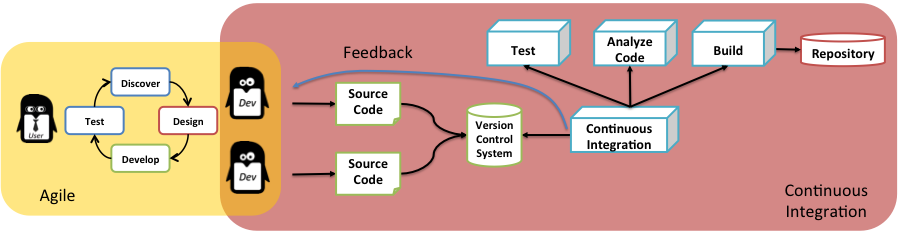
Les déploiements sont ensuite réalisés par les équipes opérationnelles qui gèrent les environnements de pré-production et de production. Ces environnements comprennent les serveurs, les systèmes d’exploitation et les middlewares nécessaires au bon fonctionnement de l’application.

Il y a encore peu de temps, ces différents environnements étaient gérés manuellement. Censés être parfaitement identiques, ces environnements présentaient toutefois des différences avec le temps, ce qui pouvait causer l’échec d’une livraison en production. Dans ce modèle, le package applicatif utilisé est toujours le même, mais les environnements sur lesquels il est déployé peuvent ne pas être parfaitement identiques.
Pour adresser cette difficulté, les équipes opérationnelles ont commencé à mettre en place des outils de gestion de configuration comme Puppet et Chef pour automatiser la gestion des serveurs sur lesquels les applications seront déployées. Au lieu d’intervenir manuellement sur les serveurs, on décrit au travers d’un outil la « recette » (packages à installer, configuration, services à démarrer…) à utiliser pour configurer les serveurs : la même recette est ensuite appliquée dans tous les environnements. Ce type d’approche permet de beaucoup réduire les différences d’un serveur à un autre. Cependant, tout ne pouvant pas être géré par l’outil de gestion de configuration, on constate tout de même l’apparition de légères différences avec le temps.
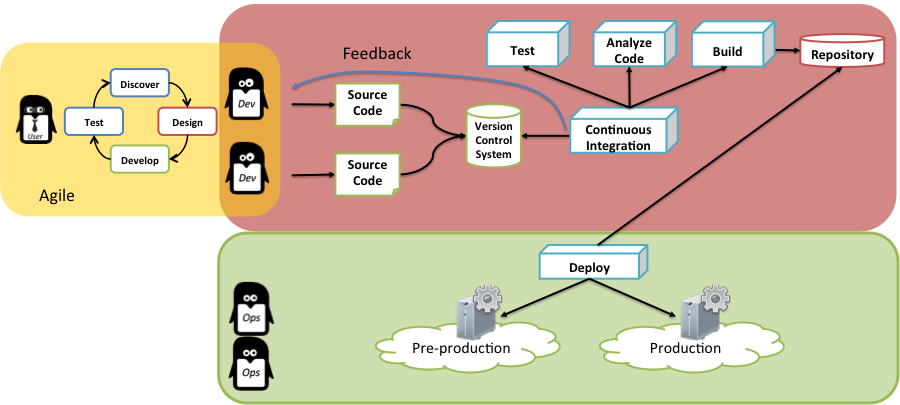
Le développement du Cloud computing, et la possibilité de mettre à disposition très rapidement de nouvelles ressources, a permis l’apparition d’une nouvelle méthode pour se prémunir de ce risque. Au lieu d’essayer de maintenir des environnements identiques dans le temps, il suffit de les recréer à chaque livraison applicative.
Dans cette approche, les environnements sont dits « immuables » : les ressources sont créées à partir d’images de serveurs de référence, et configurées lors du déploiement de l’application. Elles ne seront plus modifiées. Lors de la livraison suivante, de nouvelles ressources seront créées, et les anciennes seront supprimées.

Cette approche n’est pas encore parfaite. Imaginons un déploiement en production quelques jours après le déploiement en pré-production : il est possible que pour certains middlewares la version ait légèrement évolué sur les repository sur lesquels on s’appuie.
Il serait ainsi possible de partir de la même image de référence, utiliser la même recette de configuration mais arriver à des résultats légèrement différents. De plus, la ré-installation complète lors de la livraison peut prendre du temps, ce qui peut être incompatible avec les contraintes de déploiement de certaines applications. Une solution plus aboutie existe depuis quelque temps : au lieu de faire l’installation et la configuration lors du déploiement, elle est faite pendant la phase de build de l’application. On prend ensuite une image de la machine résultante, et il ne reste plus qu’à créer des serveurs à partir de cette image pour déployer.

On constate que l’artefact applicatif a évolué : au lieu d’être simplement le package de l’application, c’est maintenant une image de machine complète prête à être utilisée. Ce qui donne la garantie d’avoir exactement le même serveur dans les différents environnements. A noter au passage, au lieu de générer une image de serveur, ce processus pourrait générer un container (Docker par exemple).
A titre d’exemple, voilà ce que cela pourrait donner avec des outils comme Sonar, Maven, Nexus, Jenkins, Puppet, Packer ou Cloud Formation :
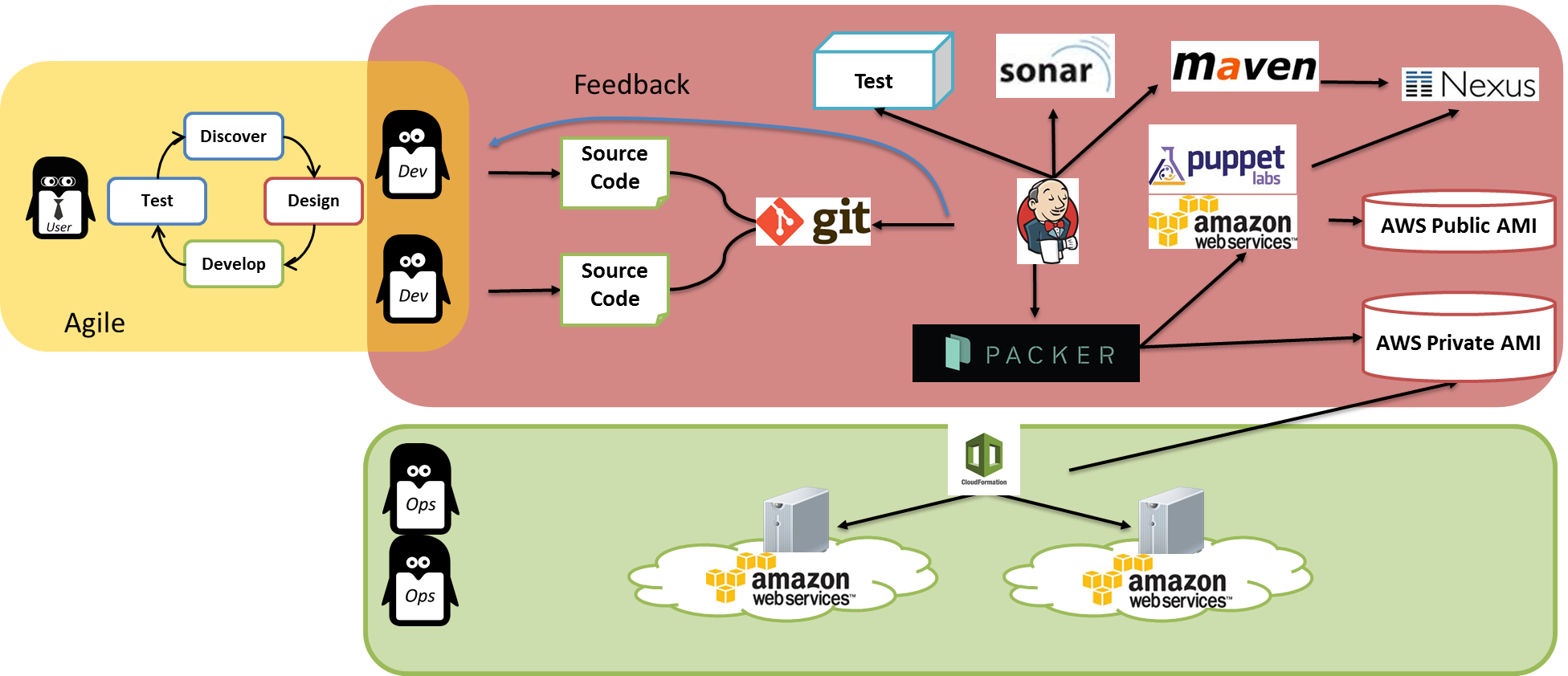
Cette approche est très prometteuse et très efficace dans le cloud, en particulier pour le traitement d’applications qui s’adaptent à la charge en ajoutant ou supprimant des serveurs automatiquement. En revanche, elle soulève de nouveaux défis. Comment gérer les variables qui sont différentes entre les environnements alors qu’on part de la même image de machine avec l’application installée ? Comment gérer les responsabilités entre les équipes de développement et les équipes d’opération alors que la configuration du serveur est maintenant faite pendant le cycle de développement ?
Commentaires :
A lire également sur le sujet :





