
AWS Summit Paris 2016 : Deep Dive S3, le stockage Cloud

La 5ème édition française de l’AWS Summit a eu lieu le 31 Mai 2016 au Carrousel du Louvre, et a rassemblé les différents partenaires de l’écosystème AWS, dont D2SI fait partie. Près de 2500 participants ont assisté à cette journée, composée de 17 sessions dont une session technique consacrée à S3 (Simple Storage Service), produit phare de l’offre AWS.
Nous revenons ici sur cette session, présentée par Nicolas Guillaume, Software Development Engineer S3, afin de partager avec vous ce “deep dive” sur les bonnes pratiques, recommandations et optimisations en termes d’usage et de coûts de ce service né il y a plus de 10 ans maintenant.
Présentation d’Amazon S3
Le stockage dans le cloud d’Amazon se compose en 3 types de services :
- stockage fichier via le service EFS (encore en beta)
- stockage bloc via EBS dans EC2
- stockage objet via S3 et Glacier, que nous allons explorer dans leurs moindres recoins
À noter que EFS et EBS ne sont pas disponibles à l’extérieur du VPC, alors que S3 est accessible en public en HTTP(S), si on a paramétré les droits.
S3 est utilisé dans de nombreux cas, aussi bien pour de la synchronisation de fichier et de partages, que de la sauvegarde et mise en place d’archive pour par exemple des Plans de Reprises d’Activités (PRA).
S3 est aussi un élément clé dans les infrastructures dites “serverless” et peut interagir avec de nombreux autres services AWS comme Lambda ou encore SQS.
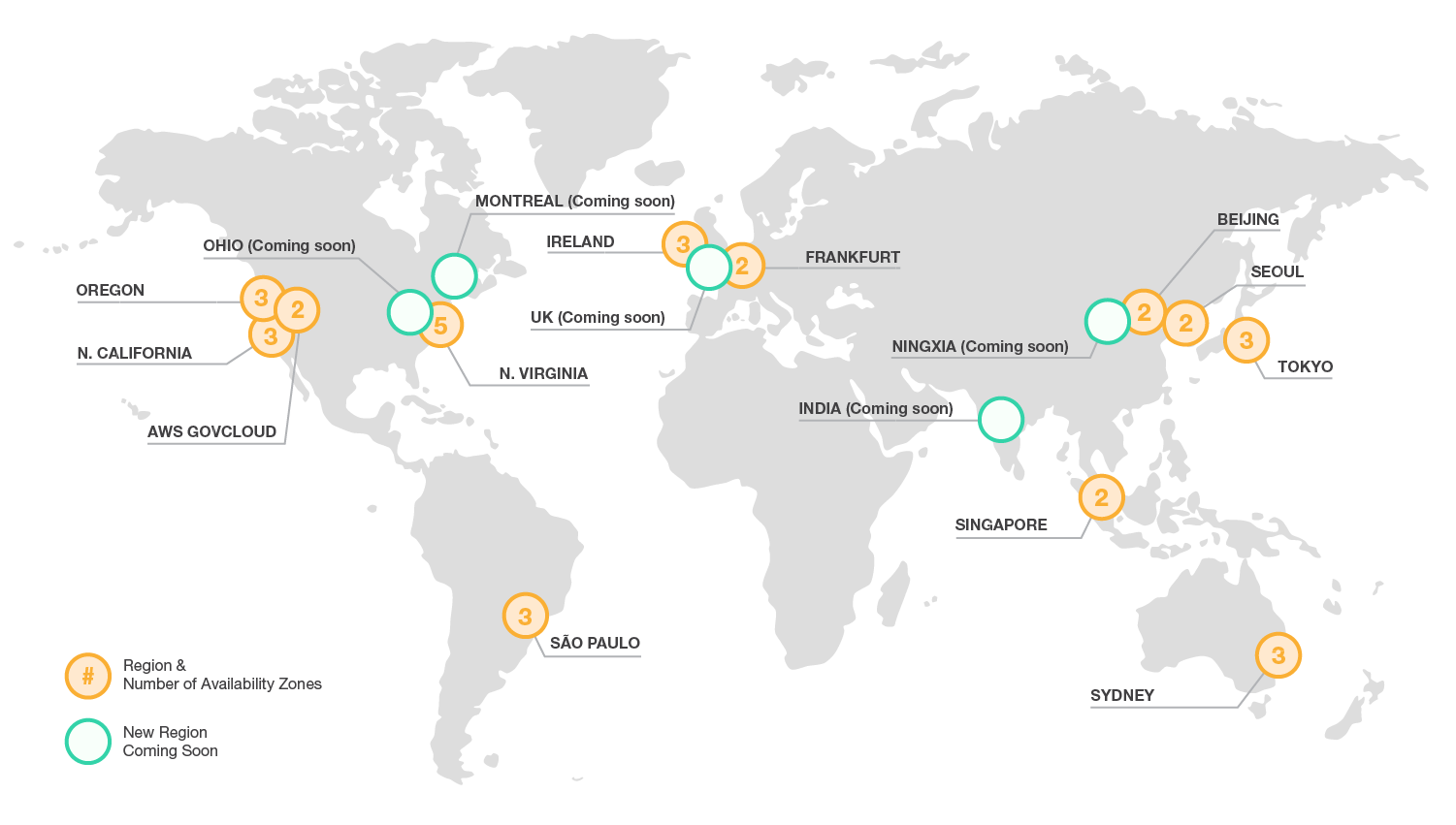
Infrastructure AWS
Les fichiers peuvent être stockés dans l’une des 12 régions dans laquelle AWS est actuellement présent, on peut si on le souhaite répliquer le contenu entre ces régions via le “Cross Region Replication” ou encore, via l’option “Transfer Acceleration” – sortie récemment – utiliser un des 54 “edge” mondiaux (dont 3 en France) de l’infrastructure d’Amazon qui permet de délivrer, au plus près de l’utilisateur final, le contenu auquel il souhaite accéder sur S3, et en conséquence accélérer le téléchargement et la mise à disposition du fichier.

La garantie de durabilité (99,999999999%), disponibilité et élasticité d’Amazon sur S3 rend ce service attractif et souple pour le stockage. Dans le domaine de la santé connectée par exemple, Philips Healthcare stocke pas moins de 15.000 téra de données sur S3 …
Quand on stocke de nombreuses données dans les nuages, il n’y a pas forcément un besoin de récupérer cette donnée immédiatement ou de manière fréquente. C’est pour cette raison qu’en dehors du stockage “Standard” et “à chaud” dans S3, AWS a mis en place deux autres possibilités de stockage qui permettent de réduire les coûts (comme on peut le voir dans le comparatif ci-dessous), et ainsi optimiser sa gestion et l’usage du cloud au quotidien.
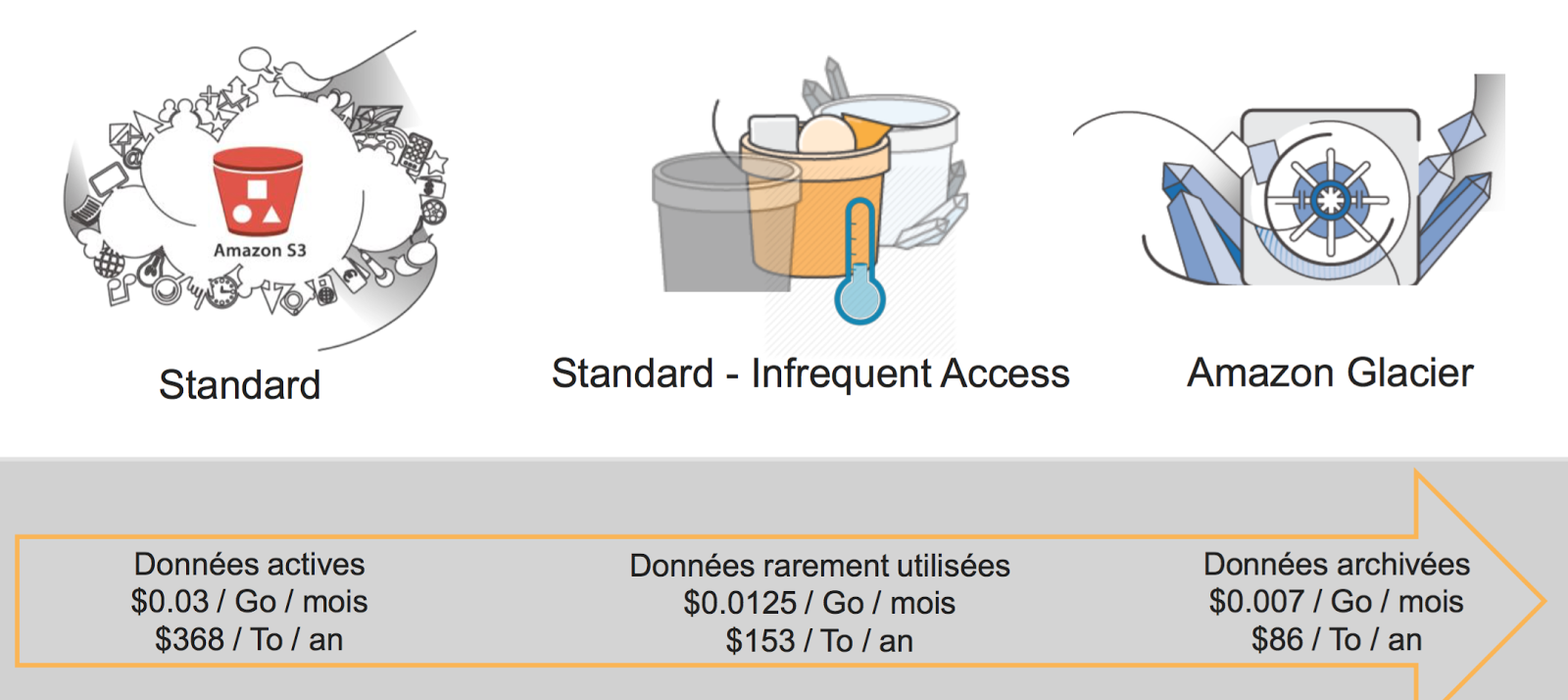
Tarifs Amazon S3 (Prix indicatif sur la région Irlande au 14 Juin 2016, voir ici pour plus de détails)
- S3 Standard IA (Infrequent Access) : sorti en Septembre 2015, offre le même niveau de durabilité et à un 9 près de disponibilité qu’un S3 Standard (99,99% vs 99,9%) tout en étant de performance identique en terme de latence et de débit que S3 Standard. Ce service de stockage prend tout son sens pour des données très peu demandées, dont on peut avoir besoin très rapidement, mais pas de manière fréquente. Par exemple, dans le cadre d’un PRA (plan de reprise d’activité).
- Glacier : ce service “gèle” la donnée sur une longue durée. Avec un temps de récupération oscillant entre 3 et 5 heures, Glacier est pratique pour l’archivage de données sur la durée et le long terme ainsi qu’en remplacement des bandes magnétiques.
Automatisation et cycle de vie
Les « lifecycle policies » sont utiles pour automatiser la gestion entre les différents types de stockage et optimiser sa consommation, et donc les coûts.

Les nombreuses possibilités offertes par les lifecycle policies au quotidien
Les lifecycle policies vont ainsi nous permettre de passer d’un type de stockage à l’autre une fois une certaine période passée . Dans l’exemple ci-dessous, si on estime qu’au bout de 30 jours le fichier est très peu sollicité mais doit être disponible rapidement, il passe ainsi en Standard-IA. Au bout de 365 jours on peut lancer l’archivage vers Glacier de façon automatisée, et ainsi optimiser ses coûts de stockage.

Exemple: lifecycle policies de transition entre S3 Standard, Standard-IA et Glacier
Versioning
Le versioning est une autre option disponible dans S3, et qui permet de gérer au mieux ses objets, en gardant une trace des différentes évolutions, par exemple, de son code pour éventuellement revenir à une version précédente. Le versioning offre aussi une protection contre une suppression accidentelle ou encore une ré-écriture sur un fichier, puisqu’à chaque upload une nouvelle version du fichier est créée pour ne garder que les plus récentes.

Si on souhaite sur la durée supprimer automatiquement les anciennes versions liées à notre versioning pour garder que les plus récentes, on peut le faire via les “lifecycles” sur une période pré-déterminée. Quand on supprime une ancienne version d’un fichier dans le versioning, un “delete marker” (marquage de suppression) est mis en place en remplacement du contenu. Ce delete marker retournera une erreur 404 lorsqu’on souhaite y accéder.
 Le “delete marker” qui vient en remplacement du contenu n’est pas facturé sur S3 : il ne consomme que très peu de place.
Le “delete marker” qui vient en remplacement du contenu n’est pas facturé sur S3 : il ne consomme que très peu de place.
Sur la durée, vu qu’on souhaite automatiser la suppression des anciennes versions, de nombreux “delete markers” vont apparaître au fil du temps, ce qui va être pénalisant pour les performances de listing de contenu dans S3.
Pour un usage efficace on va donc aussi automatiser la suppression des “delete markers”, toujours avec les lifecycles, pour ne garder que les versions des fichiers inférieures à 30 jours .
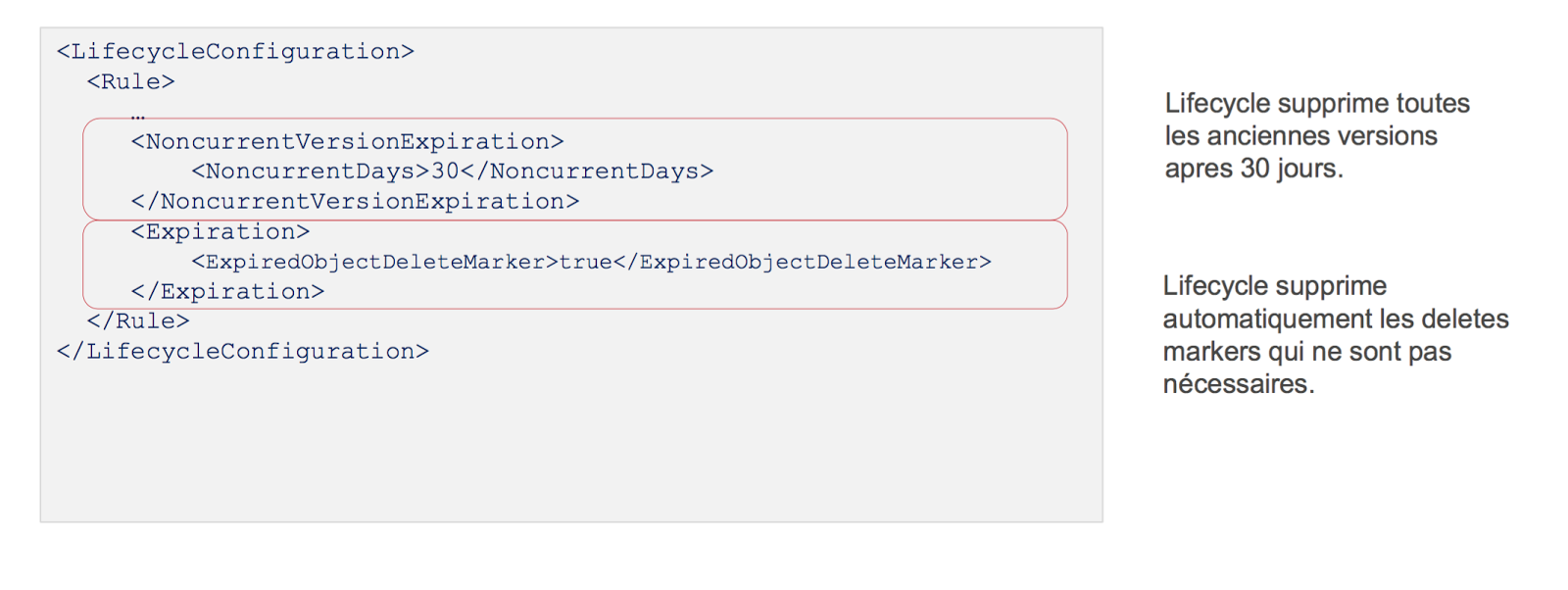
Exemple : lifecycle de suppressions des anciennes versions et des delete markers
Pour éviter toute perte de fichiers ou tentative de piratage lorsque par exemple les identifiants (access et secret key) sont publiés – par erreur ou involontairement – sur internet, la limitation des droits d’écritures et du MFA est une des bonnes pratiques pour limiter au maximum ce genre d’inconvénients.

Conseils de sécurité sur les droits d’écriture
Optimisation des application pour S3
Pour tirer le meilleur parti des avantages et de l’infrastructure de S3 il existe plusieurs optimisations et bonnes pratiques.
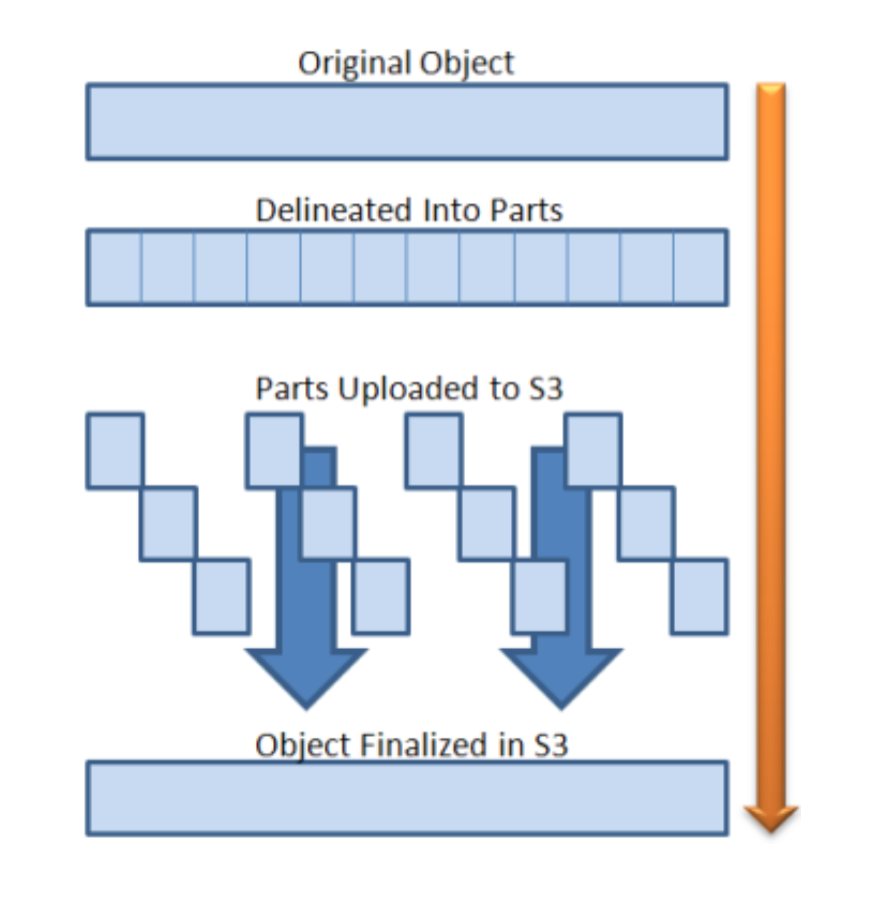 Le “multipart upload” offre la possibilité de découper l’envoi de gros fichiers (Amazon le recommande à partir de 5Go le fichier) en plusieurs morceaux (allant de 1 à 10.000 morceaux), pour permettre via la parallélisation de profiter au maximum du débit sur le réseau. En cas d’interruption au milieu de l’envoi, il est possible d’envoyer uniquement les morceaux manquants de façon à ce qu’à la fin de l’upload, tous les morceaux puissent être rassemblés et former le fichier qu’on souhaite envoyer.
Le “multipart upload” offre la possibilité de découper l’envoi de gros fichiers (Amazon le recommande à partir de 5Go le fichier) en plusieurs morceaux (allant de 1 à 10.000 morceaux), pour permettre via la parallélisation de profiter au maximum du débit sur le réseau. En cas d’interruption au milieu de l’envoi, il est possible d’envoyer uniquement les morceaux manquants de façon à ce qu’à la fin de l’upload, tous les morceaux puissent être rassemblés et former le fichier qu’on souhaite envoyer.
Pour choisir efficacement la taille et le nombre de “parts” il suffit de trouver un bon compromis entre un trop grand nombre de “parts” – et de facto de nombreuses requêtes “PUT”- qui entraînerait une augmentation des coûts VS un petit nombre de “parts” de grande taille qui ne profiterait pas pleinement de la bande passante disponible et donc de l’intérêt et usage du multipart.
Le choix du découpage se fait au niveau de l’application (la CLI AWS, par exemple, ne fait pas le découpage par elle-même) et dans son intégration avec l’utilisation du SDK AWS, ce qu’il faut savoir par rapport au multipart upload, c’est que celui-ci se décompose en trois parties :
- L’initialisation : celle-ci débute en envoyant une requête a Amazon S3 l’informant de l’initialisation du multipart. S3 retourne ensuite un ‘upload ID’ qui va permettre de lier tout les morceaux qu’on va envoyer en étape 2.
- L’envoi des parts : On précise à cette étape le numéro du morceau et sa position au niveau de l’envoi, une fois le morceau envoyé, un identifiant ETag unique par morceau est retourné. Il faut le conserver pour l’étape qui suit celle du rassemblement des parts.
- Le rassemblement : Pour compléter l’envoi et demander à S3 le rassemblement des objets, il faut lui fournir l’upload ID retourné en étape 1 ainsi que l’identifiant ETag de l’étape 2, avec le numéro de part auquel il est rattaché. On peut ainsi rassembler nos différents parts.
Lorsqu’un multipart upload est incomplet (stoppé au milieu à cause d’un problème réseau par exemple), les morceaux sont conservés sur S3 mais non listés ce qui entraîne une facturation pour le stockage. Ces morceaux incomplets peuvent rester indéfiniment, tout en étant inexploitables. Pour remédier à cela il est possible de faire en sorte qu’au bout de 7 jours les multiparts upload qui sont incomplets soient supprimés de S3, via une lifecycle policy .

 Pour récupérer le plus rapidement un objet sur S3 on peut paralléliser les téléchargements via par exemple le process de “Byte serving” ou “Range Requests” qui permet de demander uniquement une partie du fichier sur cette requête HTTP, et de lancer en parallèle une deuxième requête qui demandera une autre partie du fichier…
Pour récupérer le plus rapidement un objet sur S3 on peut paralléliser les téléchargements via par exemple le process de “Byte serving” ou “Range Requests” qui permet de demander uniquement une partie du fichier sur cette requête HTTP, et de lancer en parallèle une deuxième requête qui demandera une autre partie du fichier…
Dans le cas d’une interruption dans le téléchargement, il est toujours possible de reprendre là où il s’est arrêté.
Autre cas d’optimisation de l’usage de S3 : pour optimiser les performances de recherche quand les fichiers sont nombreux, on conseille d’utiliser un second index qui contiendra les metadata des fichiers, et permettra de les trouver et récupérer plus facilement.
Dans un cas ou on aurait plus de 100 Transactions Par Seconde (TPS) sur notre bucket S3, une méthode pour optimiser au mieux les transactions consiste à utiliser une valeur aléatoire sur nos clés dès le début de celle-ci et permettre ainsi de partager et répartir la table de partition du bucket entre les différentes clés.
Pour varier les valeurs des clés on peut utiliser une valeur aléatoire ou encore la date inversée avec les secondes au début.

Retrouvez l’intégralité de la Session Deep Dive S3 du Summit AWS Paris 2016 ci-dessous :
Automatisation, Big Data, DevOps, Désautomatisation… tous ces sujets seront abordés lors du TIAD 2016. Rejoignez-nous !

Commentaires :
A lire également sur le sujet :






