
Droit au but avec la data : l’OM lance son Data Lab

Le sport, un terrain propice à la révolution data ? On savait déjà la NBA friande de données depuis plusieurs années, en France c’est l’Olympique de Marseille qui a donné le coup d’envoi en 2020 avec la création de l’OM Data Lab, un laboratoire d’innovation autour de la data, de l’intelligence artificielle et du machine learning. Devoteam Revolve est fier d’avoir pu contribuer à ce projet aux côtés d’AWS et des équipes de l’OM.
Frédéric Cozic, CTO et Benjamin Prato, Head of Cloud & IT à l’OM ont piloté ce projet d’innovation. Ils répondent à nos questions sur les enjeux de cette transformation, le rôle de la data dans leur stratégie, et le choix du Cloud AWS comme moteur de cette nouvelle plateforme technologique.
Pouvez-vous présenter votre projet de transformation digitale ?

Nous avons lancé un projet de transformation digitale en janvier 2019. Notre objectif est d’accélérer sur l’innovation et de doter l’OM d’une nouvelle plateforme technologique qui puisse nous aider à atteindre nos objectifs sportifs et business. Cela correspond au moment où nous avons repris l’exploitation commerciale du stade; nous avons fait un état des lieux technologique, et constaté que nous avions de nombreuses briques segmentées et vieillissantes, qui ne prenaient pas en compte les enjeux et l’utilité de la data. Nous avons fait table rase de tout cela. Nous sommes partis d’une plage blanche pour imaginer ce qui pourrait être le nouvel écosystème technologique pour l’OM, un catalyseur pour le développement business et sportif, avec la donnée au cœur de cette stratégie.
Durant 18 mois nous avons travaillé sur la refonte de toutes les briques de notre système d’information : site web, application mobile, CRM, outils de gestion commerciale, comptabilité, RH. Nous avons revu toutes ces briques métier, et en parallèle nous avons évangélisé la donnée en interne comme un levier de développement. Avec pour objectif de mieux décider, décider plus vite, mieux vendre, trouver de nouvelles opportunités…

Comment la data s’insère dans ce projet ?
A l’issue de cette refonte, nous avons fait le constat que nous avions de nombreuses initiatives autour de la donnée, menées notamment avec AWS et Devoteam Revolve. Nous avons consolidé un Datalake, que nous souhaitions utiliser comme fondation pour construire d’autres projets. A ce moment, nous avions atteint notre limite sur les enjeux Data.
Pour continuer à créer et à innover, à utiliser la donnée pour de nouveaux usages, il nous fallait nous entourer de partenaires externes. Nous avons donc regroupé plusieurs initiatives existantes liées à la donnée au sein de l’OM dans un laboratoire d’innovation, le Data Lab. Autour de ce Lab, nous voulons rassembler des partenaires, startups, écoles d’ingénieurs, chercheurs, entreprises comme AWS ou Revolve et développer en commun des projets d’innovation. Par exemple, optimiser le remplissage du stade en utilisant des modèles de ML et capitaliser sur l’historique de données de ventes du stade. Nous attendons également beaucoup du Machine Learning et de la détection vidéo pour améliorer le scouting, l’identification des jeunes talents du football. Nous avons donc regroupé ce type d’initiatives internes dans le labo afin de de trouver des partenaires pour travailler sur ces sujets, avec la data comme fil conducteur.
Nous avons vu un niveau de maturité technique supérieur sur les stacks data, IA, et ML côté AWS, d’où le choix du cloud AWS
Comment ce projet a changé votre approche de la data ?
Comme toute entreprise nous avions de la data, mais nous n’avions pas capitalisé dessus pour répondre à nos besoins marketing et sportifs. La data était en partie utilisée côté business, mais nos outils n’étaient pas vraiment pensés pour l’exploiter. Nous avions des outils conçus pour la gestion, et nous utilisions la data par dessus. Aujourd’hui, tout est articulé autour de la donnée, l’écosystème est conçu de façon à faire transiter la data entre nos différentes bases de données, et ainsi pouvoir mieux stocker, mieux segmenter, prévoir nos besoins actuels et nos besoins futurs. Nous avons aussi développé une véritable stratégie data sportive, autour du scouting, de l’analyse de performances, du médical, etc. Nous avons pensé la donnée pour pérenniser son usage.
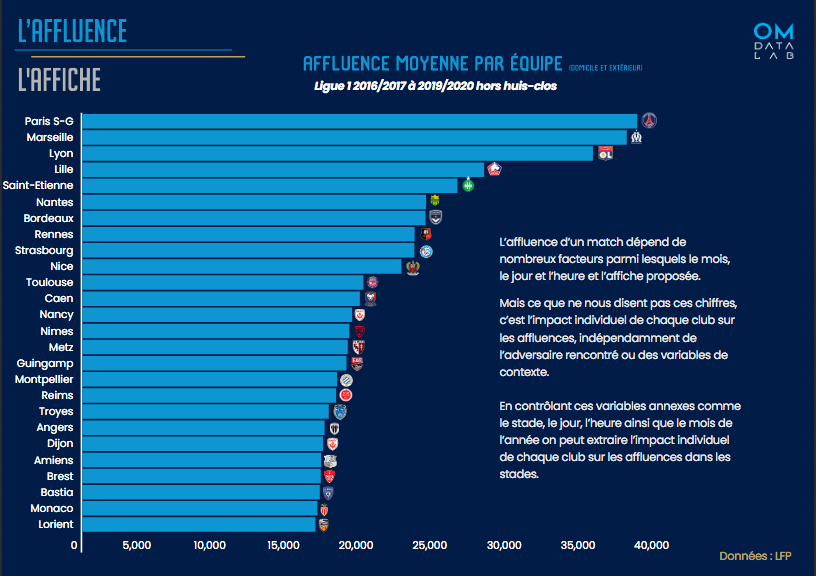
Source : Etude OM Datalab – L’impact de l’OM sur l’affluence dans les stades et les audiences télés
Comment et pourquoi avez-vous choisi le Cloud AWS ?
Au démarrage du projet data, nous avons réfléchi au meilleur moyen technique pour le mettre en place. Déployer ce type de solution et en garantir la pérennité est un vrai challenge. Nous avons rapidement écarté les solutions on premise : nous n’avions pas la capacité pour, elles demandaient beaucoup de gestion, et surtout elles risquaient de nous limiter technologiquement. Nous avons donc regardé du côté des principaux acteurs du marché du Cloud, mais nous avons vu un niveau de maturité technique supérieur sur les stacks data, IA, et ML côté AWS, d’où le choix du cloud AWS. Sagemaker et les services managés, briques de stockage pour les datalakes… AWS reste l’acteur le plus avancé sur ces sujets.
Quels avantages attendiez-vous du passage au Cloud ?
À l’origine, ce sont les besoins liés à la data qui ont déclenché le passage au Cloud : la scalabilité, les possibilités de stockage, le fait de pouvoir stocker dans les zones de notre choix. Le Cloud nous assurait le plus large éventail possible pour répondre à nos besoins. Au-delà de la data, nous avons un projet de Go to Cloud sur plusieurs années. Nous utilisons aussi le Cloud pour notre système d’information. Avoir l’option d’aller dans le Cloud en plus du on premise nous permet de déployer plus rapidement, de mettre en place des architectures plus scalables, plus sécurisées, plus avancées. Cela permet aussi de baisser les coûts : il y a une économie de coût du run, et cela prend moins de temps à faire, il donc un gain en termes de jours/homme. Le stockage sur le Cloud est économiquement très avantageux. Le serverless est également très intéressant, notre datalake utilise de nombreux workloads serverless qui absorbent la donnée, la dispatchent, la classent, la nettoient, et la plupart de ces workloads sont en dessous de l’offre Free tier, ou coûtent très peu. Le traitement des flux de données en serverless est vraiment très avantageux comparé aux solutions on premise.
Quels types de workloads serverless utilisez-vous ?
La simplicité de gestion, la scalabilité et les gains de coûts offerts par le serverless en font un choix de prédilection. Nous utilisons principalement Lambda, avec des langages en fonction des besoins : Java, Scala, et beaucoup de Python. En dehors de Lambda, nous utilisons aussi SQS, des notifications SNS, Kinesis pour les données plus véloces, et AWS Fargate pour les traitements trop volumineux pour les lambdas.

Est-ce que vous travaillez également avec Sagemaker ?
Oui, nous utilisons Sagemaker sur la partie ML Ops, pour accélérer le pipeline de création des modèles. Pour l’instant, nous n’utilisons que les briques de base de Sagemaker, comme Batch Transform, le endpoint API, et les briques de modèles et d’entraînement.
Quel type de données partagez-vous au sein du Datalab ?
Nous partageons de la donnée de gré à gré, en fonction de nos partenaires, par exemple des données commerciales anonymisées, pour essayer de trouver des segmentations et de nouvelles opportunités business. Il peut aussi s’agir de données issues d’un fournisseur de données sportives; ces données sont récupérées et exposées d’une autre manière. Cependant, nous excluons toute donnée non anonymisée, ainsi que les données d’ordre médical ou confidentiel.
Nous attendons d’un partenaire qu’au-delà de l’apport technique, il soit une extension de l’équipe
Quelles compétences avez-vous sollicitées auprès de Devoteam Revolve ?
Il y a eu plusieurs phases. Dans un premier temps nous avons travaillé sur la mise en place de notre cœur Cloud, la landing zone, et Devoteam Revolve nous a apporté ses compétences en automatisation, ops, réseau et système, infrastructure as code. Nous avons aussi sollicité de l’aide en développement car certaines applications devaient être refactorées pour la landing zone.
Dans un second temps, Devoteam Revolve nous a aidé à accélérer sur la partie Data : ETL, chargement de données dans Redshift, traitement de gros volumes de données. Nous menons aussi des ateliers autour de la donnée et de la Data Science avec les intervenants de Revolve.
Qu’avez-vous apprécié dans l’accompagnement de Devoteam Revolve ?
La relation avec les différents acteurs de Revolve est très fluide, nous apprécions la proximité. Il n’y pas d’inertie quand nous avons besoin de ressources, ils sont là pour apporter des solutions et nous aider rapidement. Les équipes Revolve ont un panel d’expertise large, de l’automatisation à la data en passant par le réseau. Il est confortable d’avoir accès à des ressources dans des délais courts, c’est une agilité que nous apprécions beaucoup. Plus globalement, les intervenants de Devoteam Revolve connaissent la stack et la plateforme OM aussi bien que nous, c’est vraiment bien de pouvoir bénéficier de ce back up.
J’échange quotidiennement avec eux, on s’apprend des choses. C’est ce que nous cherchons, nous attendons d’un partenaire qu’au-delà de l’apport technique, il soit une extension de l’équipe.
Commentaires :
A lire également sur le sujet :






