
Au secours ! Je n’ai plus de burst sur mon EFS !

C’est avec ce titre prêt à se hisser au firmament des recommandations Google que je vous explique ici comment le blog de Revolve s’est essoufflé et comment je l’ai fait repartir.
Une histoire d’EFS
Chez Revolve on a des WordPress, bientôt trois pour être précis. J’ai pu détailler leur architecture dans cet autre article de blog.
La pierre angulaire de ces systèmes est l’EFS, qui permet notamment de partager le dossier wp-content entre les différents noeuds lors d’un auto-scaling. Et ça marche plutôt bien.
Détail, important, parce que Nicolas est un radin, il a configuré son EFS en mode « burstable« , ce qui lui offre jusqu’à 150Mo/s de débit, avec un crédit de burst jusqu’à 2To à la création. Ce qui est très confortable et pour une somme tout à fait modique comparée aux $6 par méga octet de débit et par mois qu’il aurait fallu sur un EFS en mode « provisionné ».
Malheureusement, Nicolas est un feignant et bien qu’il savait que des incidents pouvaient se produire avec les EFS en mode « burstable » il n’a pas configuré d’alarme et il s’est fait avoir.
Comprendre la perte de crédit EFS
La documentation est assez claire sur la gestion des crédits EFS, mais il faut pouvoir comprendre toutes ces informations pour pouvoir prendre la décision de correction la plus éclairée possible :
Lorsque vous créez un EFS en mode burstable, la quantité d’I/O qui vous est allouée dépend de la taille du disque, exception faite s’il fait moins de 20Go.
Si votre EFS fait moins de 20Go le débit est de 1Mo/sec. S’il fait plus de 20Go, le débit sera de 0.05Mo/sec pour chaque Go de stockage (voir tableau ci-dessous). En cas de besoin de dépassement de ce débit, pas de problème, vous pourrez continuer à traiter jusqu’à 150Mo/sec mais cela consommera votre crédit et vous le récupèrerez si vous restez en dessous du maximum suffisamment longtemps (là aussi, plus le disque est gros, plus vous pouvez dépasser souvent, voir le tableau)
A noter que le débit mesuré est calculé avec une formule sympa qui fait qu’une lecture ne coute qu’un tiers d’une écriture, donc si vous lisez 3Mo en réalité vous ne consommez que 1Mo. Si vous écrivez 3Mo par contre cela consommera 3Mo. Tous les détails sont dans la documentation.
| File system size (GiB) | Baseline metered throughput (MiB/s) | Burst metered throughput (MiB/s) | Maximum burst duration (Min/Day) | % of Time file system can burst (per day) |
|---|---|---|---|---|
| 10 | 0.5* | 100 | 7.2 | 0.5% |
| 256 | 12.5 | 100 | 180 | 12.5% |
| 512 | 25.0 | 100 | 360 | 25.0% |
| 1024 | 50.0 | 100 | 720 | 50.0% |
| 1536 | 75.0 | 150 | 720 | 50.0% |
| 2048 | 100.0 | 200 | 720 | 50.0% |
| 3072 | 150.0 | 300 | 720 | 50.0% |
| 4096 | 200.0 | 400 | 720 | 50.0% |
Bien évidemment, si vous êtes en permanence au dessus du débit prévu par rapport à la taille du disque, vous allez consommer du « crédit » et vous ne le saurez pas tout de suite, en particulier parce que le crédit initial est très confortable (2To). En outre, plus l’espace occupé sur le NFS est « faible », plus vous allez dépasser souvent ce fameux maximum et donc « creuser le crédit ».
Pourquoi je me suis fait avoir
La stupidité. Voici le top 3 du pourquoi Nicolas est stupide.

Automatic upgrades going bad
WordPress, par défaut, est configuré pour effectuer des mises à jour automatiques régulièrement. Cela consiste pour ce système à télécharger les éléments sur le disque, puis à lancer un process PHP qui mettra à jour les fichiers.
Dans une stratégie de mise à jour régulière, j’ai laissé ce processus s’exécuter naturellement. Malheureusement, le processus de mise à jour n’ayant pas assez de mémoire à disposition a pris l’habitude de crasher juste après le téléchargement. Recommençant ainsi jour après jour la synchronisation sur le disque, crashant, et recommençant le lendemain, et consommant des crédits de burst au passage à chaque essai.

Cache plugin is not my friend
Le cache c’est bien. Et en particulier, sur ce blog est installé CometCache.
Le problème est que ce genre ce plugin va écrire les fichiers HTML en cache dans wp-content et donc servir tout le contenu depuis mon EFS. En outre, lors de la sauvegarde des modifications sur un article, CometCache écrira un snapshot de l’article sur le disque, et donc également sur l’EFS.

Health check killed me
Les HealthCheck c’est bien. Ca permet de savoir si le site est en ligne et sa santé globale. Mais les HealthCheck ça consomme potentiellement un chargement de page, et si c’est pointé sur une page qui est trop volumineuse… Vous allez creuser vos crédits à vérifier trop souvent que le site web est en ligne.

C’est ce que j’appelle communément « se faire heurter par l’ambulance« , un scénario doucement familier aux personnes comme moi qui on eu le plaisir de jouer à GTA San Andreas dans leur vie.
Correction(s)
Parcourant donc les différentes possibilités qui s’offrent à moi, j’ai tracé ce diagramme de décision, que je vous partage car je suis trop sympa.
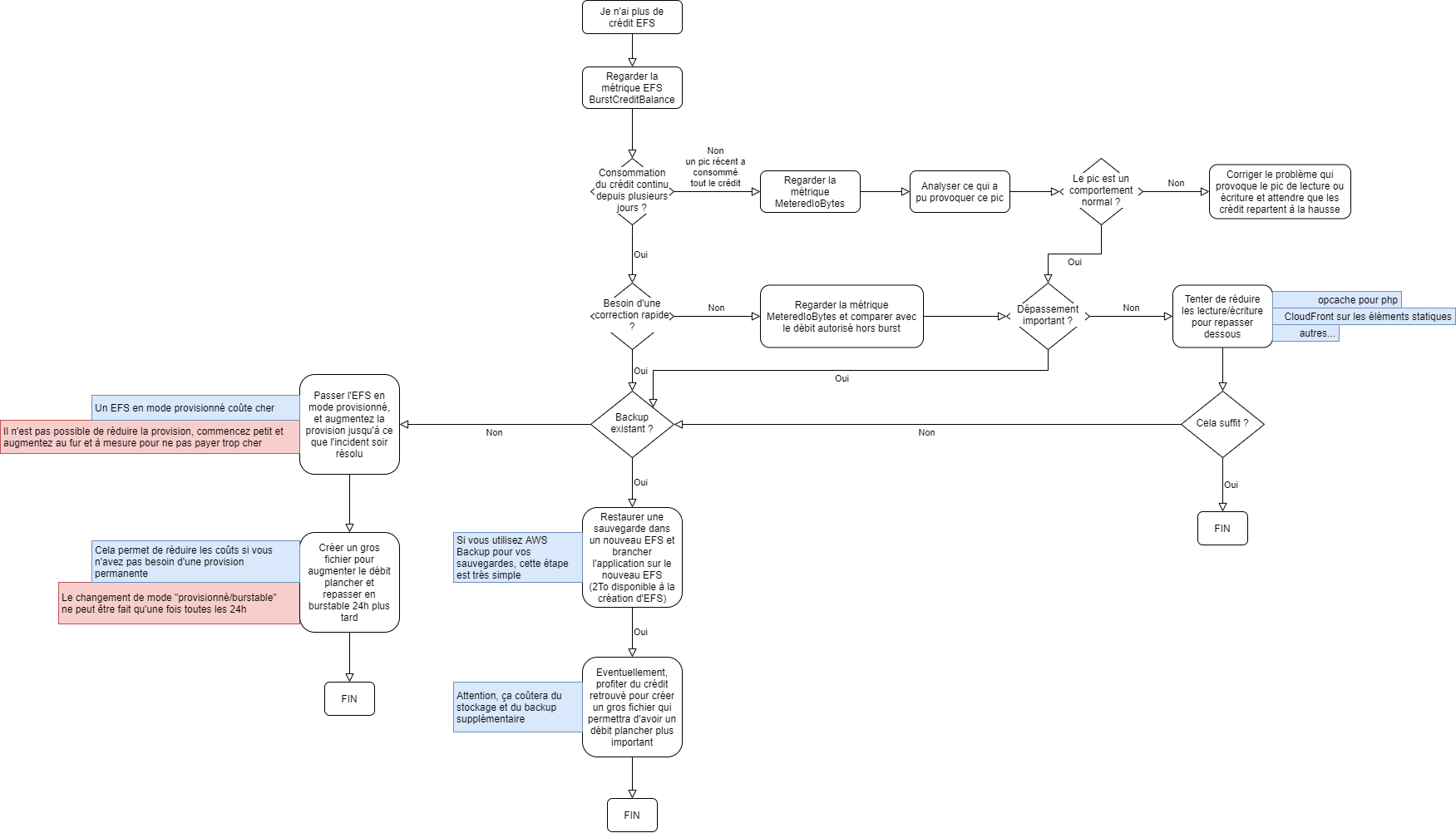
Dans mon cas, le blog étant lent depuis déjà deux jours ,et n’étant pas bloqué, j’avais quelques heures devant moi pour réfléchir. Devant le faible dépassement de débit qui pourrait me permettre de regagner du crédit, j’ai entrepris d’essayer de réduire la base de consommation par les méthodes suivantes:
- Augmentation des temps entre les HealthCheck
- Du mieux, mais pas de gain significatif qui permettrait de remonter les crédits
- Vérification de la configuration Nginx pour envoyer des Headers de cache
- La configuration était déjà correcte, les images envoient déjà un Cache-Control avec expiration importante
- Mise en place d’un cache mémoire compilé sur le PHP avec opcache
- Gain de consommation disque immédiate, et les crédits repartent à la hausse
Je me suis donc arrêté là dans un premier temps, les crédit n’étant plus consommés le site est reparti sur des temps de réponse « normaux » et j’ai recommencé à prendre « de l’avance » sur les crédits pour les moments de charge.
Des métriques ! Des métriques !
Je ne pouvais pas terminer cet article sans vous montrer « à quoi ressemble un problème de crédit EFS » dans les différentes métriques AWS, car désormais grâce à cet article cela ne vous arrivera pas.
La ligne temporelle de l’incident pour la lecture des métriques est détaillée ci-dessous:
- Incident démarré le 16/02: les crédits étant tombés à 0, le débit est ramené au plancher de 1Mo/sec (calculé en fonction de la taille du volume). Les temps de réponse s’effondrent et le phénomène est particulièrement marqué en journée lorsque le trafic est plus important.
- Le problème de lenteur est remonté par les utilisateurs le 18/02 (car Nicolas ce gros nul n’avait pas configuré d’alarme donc il savait pas que c’était en train de merder)
- Dans la soirée du 18/02, la mise en cache permet de faire repartir les crédits et remonte le plafond de débit à 105M, rétablissant des temps de réponses corrects lors des activités en journée à partir du 19/02
- Le 26/02 en soirée, j’ajoute CloudFront devant l’ALB pour mettre en caches les éléments statiques et sécuriser davantage les crédits en lecture
Débit alloué sur EFS
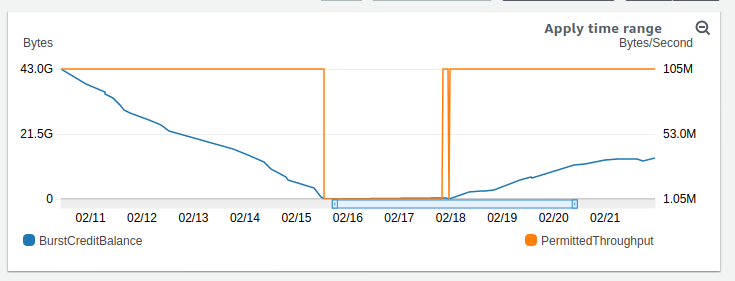
On observe la mise au plancher du débit pour cause de consommation totales des crédits EFS, puis un rétablissement de celui-ci lorsque les crédits repartent à la hausse
Débit calculé et crédit
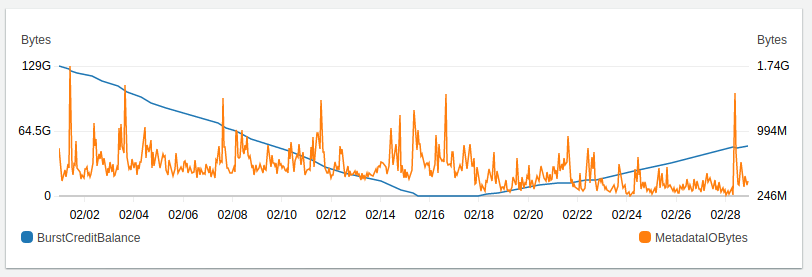
On observe que le débit mesuré consomme petit à petit le crédit jusqu’au 16 février, puis grâce à la réduction des lecture et écritures, le crédit repart à la hausse. La tendance est consolidée par le week-end du 27 février et le cache CloudFront placé le 26 février au soir. Un pic est néanmoins observé le 01/03 au matin car c’est un lundi, fléchissant la courbe de crédit mais sans l’inverser.
Temps de réponse

On observe une dégradation sur les journées des 16 et 17 février puis une amélioration à partir du 18 février au soir (mise en place d’opcache), avec des temps de réponse qui deviennent même meilleurs qu’avant le 16
Des alarmes ! Des alarmes !
Nicolas est stupide mais il a l’ambition que cela peut changer, il a donc configuré les alarmes suivantes pour être notifié en cas d’incident. Ces alarmes sont poussées dans notre Slack par une lambda. Voici ci-dessous un exemple d’alarmes que vous pouvez configurer pour vos EFS.
- Surveillance de la quantité de crédit de burst disponible sur l’EFS (BurstCreditBalance <= 100000000000 for 1 datapoints within 15 minutes)
- Surveillance des (MeteredIOBytes >= 10000 for 1 datapoints within 5 minutes)
- Surveillance de la latence moyenne des pages du blog (TargetResponseTime >= 1 for 1 datapoints within 1 hour)
Du cache ! Du cache !
Nous l’avons vu, le chargement des pages PHP est une des sources de trafic les plus régulières. Néanmoins, dans le cas d’un blog, le chargement des images reste le plus consommateur. Heureusement, dans la plupart des cas, la configuration permet d’envoyer des instructions Cache-Control pour que les clients gardent les images transmises, mais ce cache n’est pas partagé entre les utilisateurs, c’est ici que CloudFront entre en jeu.
J’ai donc rajouté le CDN CloudFront pour permettre d’économiser encore davantage sur les images. Dans l’idéal, il faudrait que les images puissent être stockées dans S3, mais le travail était trop important pour permettre cette opération dans l’immédiat, j’ai donc branché CloudFront directement devant l’ALB et je me suis assuré que les paramètres soient optimisés pour permettre de maximiser le nombre d’éléments dans le cache tout en excluant les URLs /wp-admin du cache. Des détails sur les paramètres sont disponibles dans cet article de blog AWS.
En bref
Vous devriez avoir les clés pour comprendre et corriger des problèmes de crédit sur un EFS en mode burstable. Si vous êtes toujours bloqués ou que vous avez des question supplémentaires, nos experts sont à votre disposition pour vous donner un coup de main !
Commentaires :
A lire également sur le sujet :






