
FinOps : Comment ENGIE IT optimise la gestion de ses ressources AWS

Si le Cloud facilite la mise à disposition de ressources pour les équipes métier, il demande cependant une certaine rigueur dans la gestion du cycle de vie de ces environnements. Les environnements de tests, les fichiers de backup inutilisés peuvent rapidement représenter un coût important pour l’entreprise si leur suppression n’est pas gérée de façon automatisée. Dans cet article, nous verrons comment les équipes d’ENGIE IT ont adressé la problématique des dépenses Cloud, à travers l’interview de Nicolas Beluze, Pilote de services chez ENGIE IT. Dans un second temps, nous verrons les actions de remédiation engagées pour optimiser le cycle de vie des ressources, et ainsi réduire le coût des ressources Cloud dans une approche FinOps.
Partie 1 – Interview de Nicolas Beluze, Pilote de Services, ENGIE IT
Pouvez-vous vous présenter ?
Je suis pilote de services Cloud dans la ligne de services Cloud Accelerator d’ENGIE IT. Mon rôle est de piloter une équipe d’experts Cloud et DevOps, organisée sous forme de squads agiles mises à disposition de nos clients, pour les accompagner dans le transfert de leurs activités vers le Cloud public.
Pouvez-vous présenter le contexte de la démarche FinOps ?
ENGIE IT investit depuis plusieurs années dans le Cloud public, et la multiplication de nos workloads dans le Cloud nous a poussés à réfléchir très tôt à la question de la maîtrise des dépenses. Le paiement à l’usage apporte un réel avantage, mais il demande de mettre en place une approche FinOps pour surveiller et optimiser les coûts en continu.
Comment cette démarche a-t-elle été initiée ?
La gouvernance du Cloud public est gérée au niveau du groupe ENGIE, et permet aux entités de bénéficier de tarifs négociés via l’achat massif d’instances EC2 à bas prix pour tous (savings plans AWS). Chaque entité a été ainsi sensibilisée à prendre conscience des dépenses Cloud, et à favoriser l’achat d’instances réservées pour les services managés non éligibles aux savings plans, tels que RDS, RedShift, ElastiCache ou ElasticSearch.
Au sein des équipes, nous avons pris le réflexe de réfléchir en amont des projets au scheduling des instances de machines virtuelles, à leur dimensionnement, et à la surveillance du capacity planning. Au fur et à mesure, nous avons mis en place des dashboards pour piloter l’optimisation des coûts et détecter le plus rapidement possible les dérives potentielles. C’est ce qui est détaillé dans la partie technique de l’article à travers l’exemple de la politique de stockage et de backup. Il est essentiel de surveiller en continu et d’adapter au besoin.
Comment les équipes Devoteam Revolve vous accompagnent dans cette approche FinOps ?
Les équipes Revolve ont beaucoup de maturité sur le Cloud AWS, et leur expérience du sujet nous permet d’avancer plus rapidement que si nous étions seuls à travailler sur le sujet.
Comment généraliser les bonnes pratiques FinOps ?
Nous essayons le plus possible de tendre vers les cinq piliers du Well Architected Framework dont fait partie le FinOps. Sur ce sujet, nous sensibilisons l’ensemble des acteurs de la filière IT. Nous avons de plus en plus de collaborateurs qui montent en compétence sur le Cloud, qui découvrent ce nouveau modèle et ne sont pas forcément au fait des enjeux financiers. Nous mettons en place des initiatives à la fois pour les sensibiliser, et pour améliorer en continu les pratiques FinOps et autres aspects du WAF.
Quelles sont les actions de sensibilisation ?
Le Groupe propose des webinars réguliers à l’ensemble des acteurs principaux de la filière IT d’ENGIE. Au niveau d’ENGIE IT, nous avons des sessions de partage d’expériences et de bonnes pratiques, avec des retours sur les projets Cloud menés. Il y notamment des sessions spécifiques FinOps où nous présentons les outils et frameworks mis à disposition des squads pour piloter au mieux la consommation Cloud de leurs projets et de nos clients.
Quels types d’outils utilisez-vous pour suivre la consommation Cloud ?
Nous nous appuyons sur certains outils natifs AWS comme le Cost center, mais nous développons aussi nos propres outils. En effet les informations de billing au niveau de la console AWS ne prennent pas en compte les savings plans et autres accords négociés au niveau du Groupe, nous devons donc récupérer des informations supplémentaires pour présenter la facture exacte envoyée à chaque entité. Nous avons mis en place une infrastructure avec des fonctions Lambda qui agrègent les différentes informations, les traitent pour les mettre à disposition de nos équipes sous forme de métriques Cloudwatch, métriques qui sont ensuite récupérées par l’outil de visualisation de données Grafana pour produire des dashboards de suivi de la consommation.
Quels sont vos prochains objectifs ?
Nous allons maintenir le focus sur les cinq piliers du WAF, avec pour objectif que l’ensemble des équipes ENGIE IT soient pleinement conscientes de ces enjeux. L’optimisation financière doit être intégrée dès la phase de build, puis suivie de façon continue pour s’assurer de détecter les éventuelles dérives au plus tôt. Actuellement, nous améliorons nos dashboards avec un « alerting » temps réel, de façon à ce que les équipes concernées puissent être informées dès la détection d’une dérive, et mener les remédiations nécessaires, sans attendre un reporting hebdomadaire ou mensuel. La démarche FinOps est à la fois un travail de sensibilisation, et d’outillage pour maîtriser en continu la consommation dans le Cloud.
Partie 2 – Un exemple concret d’optimisation des ressources par l’automatisation
Contexte
Les squads AWS chez ENGIE IT travaillent sur la mise en place des environnements de production, notamment sur le Cloud. L’objectif est de mettre à disposition des équipes une plus grande puissance de calcul, de la haute disponibilité, du stockage, etc. Cependant le cloud n’est pas magique, il répond à une grande partie des besoins mais peut en créer de nouveaux. Avec le temps, les ressources dont le traitement n’a pas été automatisé induisent des coûts souvent non négligeables sur une facture mensuelle à l’échelle d’une grande entreprise. Afin de prévenir ce cas de figure où des stacks, machines virtuelles ou backup obsolètes n’ont pas été supprimés, nous avons mis en place une gestion automatisée du cycle de vie.
Etat des lieux des ressources Cloud
Avant d’envisager des mesures d’optimisation FinOps, il faut mener un audit des ressources Cloud. Au sein de notre squad, plusieurs centaines de machines virtuelles ont été déployées afin de mettre en place des applications SAP. Lors de ce déploiement, l’un des enjeux était d’avoir des backups réguliers de toutes ces machines, compte tenu de la sensibilité de certaines données. Ainsi pour répondre à ce besoin, la première solution a été d’utiliser des scripts directement sur les machines, souvent lancés avec des Maintenance Windows sous System Manager. Cette solution fonctionnait correctement mais générait une grande quantité de snapshots et d’AMI et de fichiers de backup sur des buckets s3, et donc un coût supplémentaire. Dans le cas des EFS, pour chaque EFS montée, nous utilisions une EFS pour backup; par exemple pour l’EFS xxx on utilisait l’EFS xxx-backup pour gérer le backup. Le problème des backups était résolu mais en soulevait un autre : le coût de tous les backups devenus obsolètes.
Le tagging des ressources
Dans un premier temps, nous avons mis en place une politique de tagging pour répondre à cette problématique. Cette politique de tagging a été appliquée pour tous les services utilisés. Nous avons donc mis en place des fonctions Lambda et des scripts afin de s’assurer que toutes les anciennes stacks sont correctement taggées et que les nouvelles le soient également. Cette politique de tagging a permis de simplifier l’identification des applications ainsi que tous les services qui leurs sont liés. Le type de backup mis en place est défini par un tag qui permet de connaître la durée du backup, et en même temps facilite l’action automatique à mettre en place. On peut également grâce à cette politique de tagging effectuer différents niveaux et types de surveillance de facturation en ciblant des applications, des services, des types de backups, etc…
Le tagging se fait en deux étapes:
- La première étape consiste pour nos équipes à lister dans un fichier xslx l’ensemble des ressources sur le compte à tagger, pour ensuite utiliser un script qui communique avec AWS Migration Hub et nous retourne un fichier avec la liste de nos instances avec le migration id, et les enregistre sous un nom d’application dans AWS Migration Hub. Enfin ce fichier est posé sur AWS S3 pour qu’il puisse être exploité.
- La seconde étape est essentiellement le déclenchement chaque jour à 9h d’une Cloudwatch rule qui invoque une lambda. La fonction invoquée se réfère au fichier sur S3, effectue le tagging de l’ensemble des ressources listées et produit un rapport qu’elle envoie par mail aux utilisateurs via AWS SES
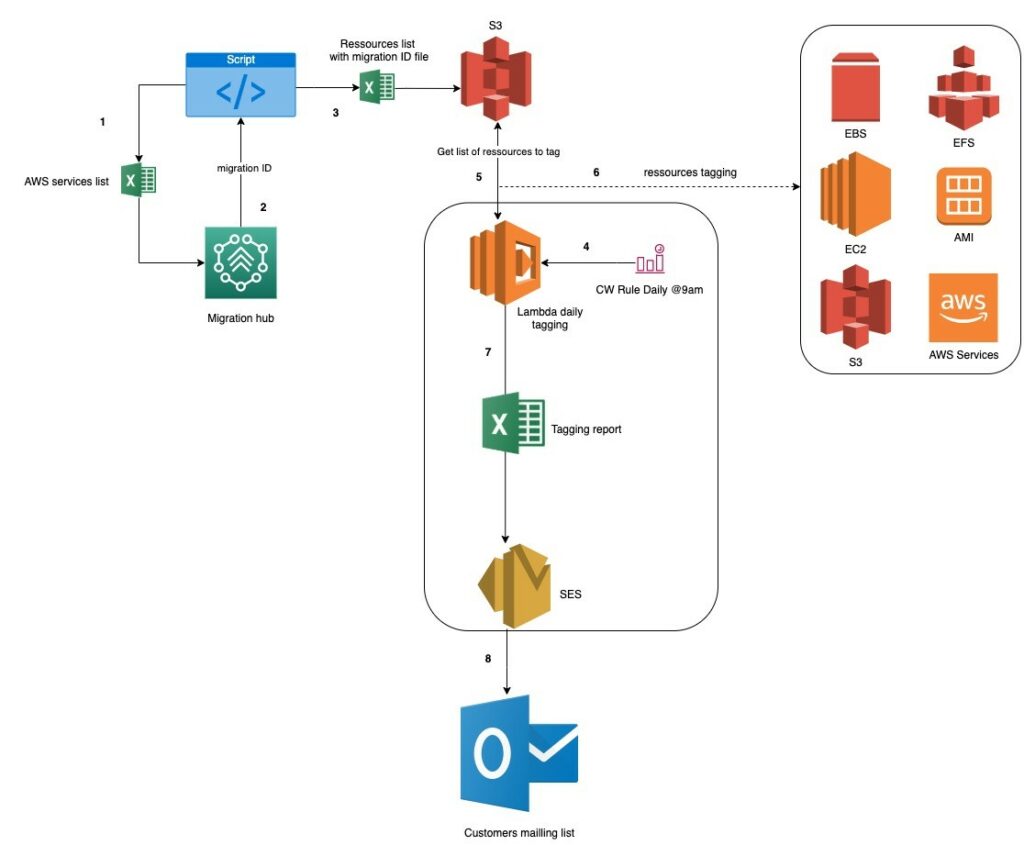
Ensuite afin de réduire les coûts, un script effectue un clean up des comptes afin de les purger de tous les éléments obsolètes. Là encore le tagging a servi à supprimer les éléments de tests et les ressources obsolètes.
Enfin pour résoudre au mieux notre problème de coûts et en gardant nos solutions de monitoring, nous avons axé nos actions sur :
- Dashboarding et monitoring
La mise en place de dashboards basés sur des métriques customs et standards avec Cloudwatch nous a permis de surveiller de façon plus précise nos services. A l’aide des dashboards il est plus facile de se rendre compte si le dimensionnement a été mal réalisé, faire des analyses post mortem en cas de fail et voir les fréquences d’usages de nos volumes, EFS et le trafic réseau.
- AWS backup
Le service AWS backup a été utilisé pour les sauvegardes des EFS. Ce service managé correspond parfaitement au besoin et offre toute la flexibilité d’un service managé. Les backups plans contiennent plusieurs règles de backups qui correspondent aux politiques définies par les équipes pour les EFS. On retrouve donc souvent un backup plan par environnement avec ses règles ou un backup plan par EFS avec ses règles spécifiques.
- Solutions custom de backup, clean up et reporting
Pour le reste de nos backup nous avons opté pour des solutions custom car le reporting proposé par AWS Backup ne répondait pas aux attentes des équipes. Nous avons donc deux grandes solutions de backup custom déployées sur nos comptes :
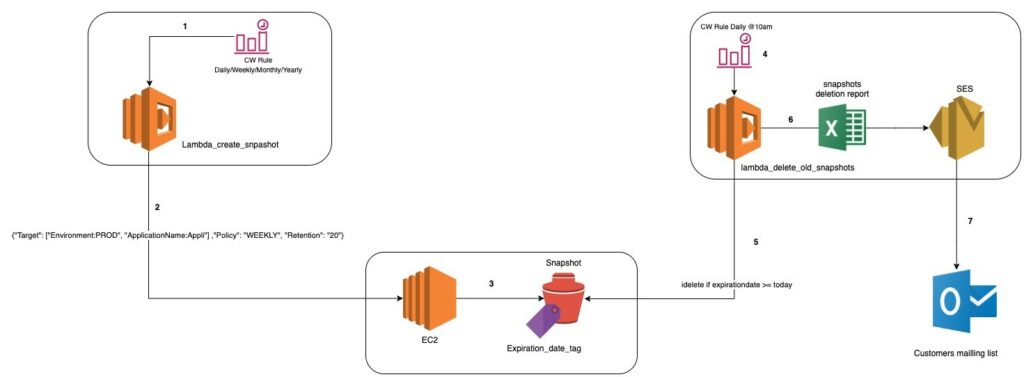
- Pour les backup EBS
Afin d’assurer correctement nos backups d’EBS nous avons opté pour deux lambdas. La première est activée par un cron qui contient le type de snapshots souhaité (Daily, weekly, Monthly, Yearly). Le type de backup indique la fréquence d’exécution du cron donc de la lambda. Une fois la première lambda activée, elle lance un snapshot des volumes EBS concernés par le payload indiqué dans le cron, avec notamment la date d’expiration du snapshot.
La seconde lambda est déclenchée quotidiennement afin de supprimer tous les snapshots dont la date d’expiration est atteinte ou dépassée. Cette lambda envoie ensuite un rapport via AWS SES sur une liste de diffusion pour que les collaborateurs puisse être informés des actions et parfois faire des vérifications
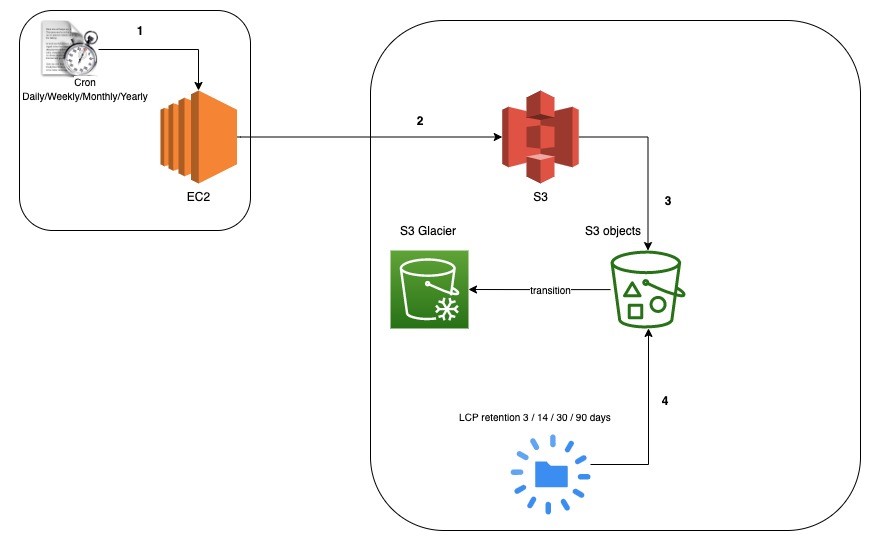
- Pour les backint de nos bases SAP
Afin de sauvegarder les base SAP, les équipes SAP ont utilisé la solution du backint.
Dans ce cas de figure, un script est mis sur l’instance EC2 contenant la base SAP afin de réaliser les sauvegardes nécessaires et les importer sur un bucket S3. Sur le bucket, des répertoires ont été mis en place afin d’ordonner les sauvegardes. Se basant sur ces répertoires, nous avons ajouté à l’aide de scripts des lifecycles policies (politiques de cycle de vie) spécifiques pour chaque répertoire. Ainsi, les fichiers sur certains répertoires sont supprimés au bout de trois (3) jours ou quinze (15) jours ou même sont envoyés sous S3 Glacier pour être supprimés sous trente (30) ou quarante (40) jours en fonction de la politique définie par les équipes.
Conclusion
La mise en place d’environnement sur le cloud dans un contexte de production, est un défi qui demande un travail quotidien et un investissement de tout instant. La définition d’une bonne politique de gestion des comptes, la maîtrise des coûts et la mise en place de solutions d’alerting et de backup sont des éléments essentiels dans ce cycle de vie pour les équipes. Il reste encore de nombreux chantiers pour une amélioration de nos usages sur nos comptes, notamment une amélioration des systèmes de reporting, des remédiations automatisés et une uniformisation totale des pratiques sur les différents comptes, mais le travail effectué par les équipes ENGIE IT a déjà permis une réduction significative des coûts d’infrastructure sur les comptes.
Commentaires :
A lire également sur le sujet :





