
Dans ta science : cartographier Internet grâce à la Data
A la croisée de plusieurs disciplines, la Data Science s’appuie sur des méthodes et des algorithmes pour tirer des informations et de la connaissances à partir de données structurées et non structurées. Encore inconnu il y a quelques années, les métiers de la Data Science et du Machine Learning évoluent très vite. Compétences, méthodes, outils… dans cette série d’entretiens, nous confrontons notre expérience à celle du marché, avec la participation de Data Scientists et ingénieurs Machine Learning externes à Devoteam Revolve.

Nous recevons aujourd’hui Nicolas Bouchaib, qui travaille chez Firstlink Bordeaux en tant que consultant Social Data Scientist.
Firstlink aide ses clients à appréhender et à mieux comprendre la donnée sociale. Contrairement à la Data Science “classique”, qui travaille surtout sur des données produites en interne, Nicolas traite des données externes, issues du web et des réseaux sociaux. L’analyse et le traitement de cette donnée permet à ses clients de mieux comprendre leurs écosystèmes numériques, les contextes sociaux dans lesquels ils se situent, et ceux sur lesquels ils souhaitent se développer en communication/marketing.
En parallèle, Nicolas est également formateur dans des écoles comme Digital Campus ou l’INSEEC.
Suivez-le sur Twitter pour une prochaine explication sur la cartographie des termes associés à la Data Science et au Machine Learning.
Quelle est ta formation ?
J’ai suivi un double cursus : en classe prépa et en école d’ingénieur, j’ai fait des maths, de la physique et de l’informatique, puis un Master en sciences de l’information et de la communication, avec de la sociologie, des sciences humaines et des méthodes digitales. Aujourd’hui, mon métier est de faire converger ces deux domaines. J’applique des méthodes d’ingénierie et de Data Science, qui habituellement sont appliquées à de l’opérationnel produit ou à des process, pour faire du marketing, de la communication et des études de positionnement et de stratégie.
Comment en es-tu venu à la Data Science ?
J’ai appris à coder en école d’ingénieur, où je me suis spécialisé en cybersécurité. Néanmoins, durant ma formation en sciences sociales, j’ai choisi de ré-orienter mes compétences vers la data science. Je me suis auto-formé sur le sujet, en complément de mes cours de Data Analyse, parce que la sécurité était un domaine de l’IT où je ne me retrouvais pas vraiment.
J’aime développer, et dans la sécurité on fait peu de scripts ou de logiciels. La cybersécurité a un aspect très “fondamental”, là où la Data Science a plutôt un aspect très concret, où le code produit un résultat, une cartographie, etc. A l’heure où la data est produite en masse, savoir coder est un vrai point fort pour les sciences de l’information ou le marketing. L’accès à la data est une arme incroyable pour les communicants.
De nombreuses entreprises font encore de la veille marketing de façon manuelle : veille sur les réseaux sociaux, enquêtes qualitatives… Le marketing data driven est déjà une réalité dans les entreprises anglo-saxonnes, en France c’est un sujet encore nouveau. Il y a un sujet à démocratiser, les entreprises cherchent à automatiser le traitement de leur données sociales pour mieux les comprendre, que ce soit à des fins de visibilité, de croissance de communauté ou d’enquêtes qualitatives. L’analyse des réseaux sociaux permet d’avoir facilement des réponses, sans mettre en place des campagnes lourdes comme on le fait dans le marketing traditionnel.
Que sont les données sociales et comment sont-elles analysées ?
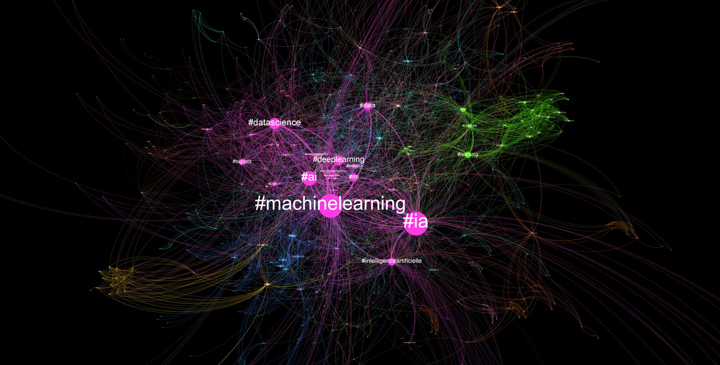
Prenons le cas d’un client qui souhaite se faire connaître sur le Web et fédérer une communauté. Mon travail consiste à extraire des données du web et des réseaux sociaux, afin de détecter des insights qui faciliteront son insertion dans cet écosystème. Il s’agit d’identifier les leaders d’opinion, et de comprendre comment est structuré le web sur le marché : ce que pensent les gens en général, comment ils discutent entre eux, quelles sont les différentes communautés, etc. Nous appliquons des concepts de data science pour cartographier le web à partir de la data, et des concepts de sciences sociales pour comprendre les dynamiques de communauté. J’ai par exemple réalisé une cartographie de Twitch qui est un travail d’analyse de la communauté.
Comment vois-tu le métier de Data Scientist ?
Je suis dans un contexte un peu particulier. Le plus souvent les Data Scientists gèrent des infrastructures de données internes, alors que je traite des données externes, issues d’Internet, pour définir une problématique de compréhension de l’écosystème.
Récupérer la donnée est une part importante du travail, même si elle est en libre accès. Il faut cibler la donnée, sinon on risque de ratisser trop large, ou au contraire de n’avoir qu’un petit pan du spectre. Il faut aussi prendre en compte le fait que sur les réseaux sociaux, l’accès à la donnée peut être bloqué ou limité. Enfin, nous devons nettoyer, lisser et mettre en forme ces données. Mais nous ne sommes pas vraiment dans la tendance actuelle d’automatisation du machine learning – notre parti pris, c’est d’abord de data visualiser, avec la cartographie, pour faire de l’analyse exploratoire, voir la donnée et permettre à un humain de la comprendre et l’analyser.
Comment se fait cette analyse ?
Pour savoir où sont les internautes susceptibles de s’intéresser à une thématique, par exemple la protection de l’environnement, nous avons besoin de comprendre les communautés, comment elles évoluent et interagissent entre elles. La data nous donne de nombreux insights, et nous devons sélectionner ceux qui sont les plus pertinents. C’est un travail de contextualisation.
Ensuite, nous allons chercher ces insights dans le dataset. Quand la communauté est identifiée, on va voir sur le réseau social comment elle interagit, on lit les messages…on ne laisse pas la machine faire le travail de A à Z, on re-vérifie par pans. La donnée sociale comporte beaucoup d’ambiguïtés et de subtilités, même pour un humain elle est parfois difficile à comprendre. Est-ce qu’un commentaire est ironique ou premier degré ? Enfin, il y aussi un travail de vulgarisation à mener. Nos interlocuteurs ne sont pas des Data Scientists, ils ne sont pas issus du milieu tech, nous devons donc pouvoir leur expliquer ce qu’est la cartographie, ce qu’elle nous permet de comprendre, et pourquoi ce que nous avançons est prouvé par la donnée. On a de beaux graphiques en 3D qu’on trouve incroyables, mais on ne peut pas les donner tels quels au client, ils ne sont pas auto porteurs.
Pour résumer les grandes étapes : mise en place méthodologique, extraction, nettoyage, data visualisation, parfois du traitement NLP (Natural Language Processing) pour donner des tendances exploratoires, recontextualisation, data analyse, et vulgarisation.
Est-ce compliqué de travailler avec des datasets à la durée de vie limitée ?
Les dynamiques de recyclage de données et d’apprentissage des algorithmes sont assez compliquées : la donnée évolue très vite, on travaille sur le comportement humain, qui est complexe, et qui évolue très vite sur les réseaux. De fait, il n’est pas simple d’entraîner des algorithmes avec des données périssables.
Développer des méthodes d’analyse de hashtag avec des modèles complexes comme les réseaux de neurones est incertain
La tendance d’hier peut très vite disparaître. Par exemple, le hashtag, qui est une porte d’entrée pour comprendre les dynamiques de discussion sur les réseaux. A une époque tout le monde utilisait des hashtags, et on pouvait facilement cartographier les hashtags pour comprendre comment s’imbriquent les thématiques de conversation. Mais plus le temps passe, moins on utilise le hashtag : les jeunes ne l’utilisent plus vraiment, il est plutôt réservé aux échanges formels dans les milieux professionnels. Développer des méthodes d’analyse de hashtag avec des modèles complexes comme les réseaux de neurones est incertain. Tout cela évolue très vite, une tendance sur twitter peut changer en quelque mois. Peut-être que demain on n’utilisera plus du tout de hashtag. On a donc comme parti pris d’avoir toujours un humain derrière les algorithmes pour faire ce travail d’apprentissage. De fait, il est compliqué de faire des modèles stables avec des données périssables.
Quels types d’outils utilisez-vous ?
Nous utilisons des scripts et logiciels propriétaires, codés en interne, et Gephi, logiciel open source de datavisualisation et de cartographie. Ce logiciel est issu du medialab Sciences Po, à qui on doit beaucoup dans l’avancée des méthodes digitales et l’analyse de la donnée sociale. Nous avons aussi des scripts développés en interne pour nos propres besoins. Pour ma part, j’utilise Visual Code Studio pour coder en Python, mais j’ai des collègues qui préfèrent utiliser Jupyter. Et bien sûr les outils fondamentaux comme Github pour le versioning.
A quel moment du cycle de vie le modèle de ML intervient-il ?
Le plus souvent, c’est après la phase de data visualisation, et de façon non automatisée. Toutes nos données ne partent pas en apprentissage. Comme on utilise le ML sur des modèles relativement simples (régression linéaires, KNN, clustering), nos modèles n’ont pas besoin d’apprendre longtemps.
Pour faire de la compréhension de texte à grande échelle, nous utilisons aussi du Natural language Processing. Le NLP nous permet d’identifier des tendances : on analyse par exemple un million de tweets pour savoir si la tendance est plutôt positive ou négative, et faire émerger une thématique. Mais nous ne dirons jamais au client que selon le logiciel, les gens sont favorables à son produit à 80%. Il y a des biais en analyse sociale, il est par exemple très compliqué pour l’algorithme de détecter l’ironie dans un tweet.
Le Machine Learning intervient quand on veut aller plus profond dans la partie exploratoire. Il fonctionne bien aussi pour détecter les leaders d’opinion : cela va au-delà du simple nombre de likes ou de follows, il y a d’autres indicateurs que de la statistique descriptive. Le ML est vraiment un outil, c’est plus une loupe qu’un rendu.
Modélisation 3D des comptes liés au Machine Learning sur Twitter
Est-il long de passer vos modèles en production ? Comment se passe le cycle test/expérimentation/production de valeur ?
Au-delà du Machine Learning en soi, nos process sont longs à mettre en place. Par exemple, nous avons développé un outil d’analyse des emojis il y a six mois; pour faire de l’analyse de sentiments, l’usage des emojis est plus facile à cerner que la sémantique. Bien que nous ayons eu rapidement des résultats intéressants, nous sommes encore dans une phase d’expérimentation, et ce type d’analyse ne produit pas encore de valeur. J’ai utilisé l’outil pour faire des études de cas sur Twitter, mais il n’a pas encore été exploité dans un contexte client car nous ne sommes pas certains de sa capacité à fournir un résultat suffisamment fiable pour un rendu client.
Globalement, que ce soit pour nos modèles de ML, le NLP ou les nouvelles façons de traiter la cartographie, nos phases d’expérimentation sont assez longues. Mais nous sommes dans un secteur qui apprend vite et qui innove beaucoup, donc on peut mettre en place une méthodologie et découvrir un nouvel algorithme quelques semaines après, plus efficace, plus rapide, donc on recommence ! La vitesse de l’innovation fait que la R&D est assez instable. Si demain le ML évolue, cela ne rend pas forcément notre modèle obsolète, mais améliorable. C’est d’autant plus vrai que nous sommes à la croisée de deux disciplines, la data science et les sciences sociales.
La veille technologique est-elle une partie importante du travail ?
Oui, chaque journée commence avec la veille sur Twitter, Medium, ou sur le web. Parfois sur Twitter, au détour d’un post avec seulement quelques likes, j’ai pu découvrir quelque chose qui allait changer la perspective de mon travail pour les deux mois suivants. C’est un très bon vecteur d’information sur ces sujets, tout comme Towards Data Science sur Medium.
Est-ce que tu travailles sur le Cloud ?
Nous l’envisageons. Jusque-là nos machines étaient suffisantes pour faire tourner nos scripts et logiciels de façon rapide, mais nous sommes dans une phase d’accélération et nous rencontrons de nouvelles problématiques. Pour spatialiser la première cartographie de Twitch, la plus volumineuse que nous ayons jamais réalisé, nous avons dû louer des VM sur des plateformes de minage de cryptomonnaie. Par la suite, on passera sûrement sur AWS.
En attendant, nous avons amélioré l’efficacité de nos algorithmes pour pouvoir continuer à les faire tourner sur nos machines, mais à court terme nous étudions les possibilités pour migrer sur le Cloud pour débloquer de la puissance, soulager nos machines, et mettre en place des méthodologies d’extraction continue. Jusqu’à maintenant, on faisait de l’extraction au besoin, de façon ponctuelle.
Mais pour Twitch et d’autres supports, nous devons passer dans une logique flux continu, et le Cloud est la meilleure solution pour répondre à ce besoin, et avoir des volumes de stockage adaptés à la croissance des données. Twitch par exemple, génère beaucoup de gigas de données pour les rendus. Passer sur le Cloud nous permettrait d’assurer la stabilité et la continuité de la récupération des données.
Quels sont les pain points ?
En premier lieu, les biais. J’ai vu récemment sur Twitter une cartographie des politiciens qui a suscité beaucoup de débats et entraîné des déductions certainement inexactes. Une cartographie ne donne pas directement des réponses, elle apporte des pistes de réflexion à creuser. Il faut aussi savoir comment elle a été construite, car là aussi on peut orienter la donnée. Et c’est une des plus grandes difficultés de l’exercice, ne pas biaiser la donnée. Dans notre domaine, la mesure n’est pas précise comme elle peut l’être dans d’autres sciences.
Une mesure en mètres est précise, exacte, mais qu’en est-il d’un avis positif, ou de la relation entre deux acteurs ? Que signifient un like, un retweet ou un follow ? En fonction des choix faits lors de la construction de la cartographie, les résultats basés sur ces indicateurs peuvent beaucoup varier. Il y a beaucoup d’interprétation dans la donnée sociale, donc il faut se méfier des biais. Ca va jusqu’aux couleurs des cartographies, par exemple on évite les couleurs vert et rouge : inconsciemment, elles peuvent être associées à bon/méchant. Aucune analyse n’est simple, parce qu’on essaie de comprendre le fonctionnement de l’esprit humain qui est complexe, mais c’est passionnant.
En l’état actuel des technos, la donnée sociale ne peut pas être privée, donc autant qu’elle soit ouverte à tous
Une autre difficulté est l’extraction de données quand le réseau social ne la mets pas à disposition. On ne peut pas passer par les API et il faut mettre en place des méthodes lourdes, qui peuvent s’avérer inutiles du jour au lendemain si le réseau social change son Javascript. Les GAFAM comprennent la valeur de leur donnée et ne veulent pas les partager, c’est un monopole exercé sur la donnée sociale qui est très gênant. Il suffit de voir à quel point Facebook comprend bien vos hobbies et centres d’intérêt.
Personnellement, je serai pour un accès ouvert à la donnée à tous, pour que le citoyen puisse s’en emparer. En l’état actuel des technos, la donnée sociale ne peut pas être privée, donc autant qu’elle soit ouverte à tous. Au moins sur Twitch, c’est plus transparent : tout le monde peut savoir qui regarde tel stream. Cela éduque sur la notion de pseudonymat. Chez Firstlink nous utilisons uniquement des données publiques : pas d’adresse mail, pas de nom, pas d’âge etc. Nous travaillons sur les contenus, et sur les pseudos, à une échelle macroscopique, donc on se détache de ce flicage à l’échelle micro, parce qu’on se rend compte à quel point techniquement c’est facile à faire.
Comment se passe une journée de travail classique ?
Nous sommes une petite équipe, on travaille par projet; je travaille sur l’innovation et la technologie, je suis celui qui code le plus. Nataniel, le fondateur est plus sur l’acquisition client, la data analyse, le rendu et la vulgarisation. Nous sommes tous Data analyst, mais je suis celui qui est le plus du côté de la Data science.
Il n’y a pas vraiment de journée type, cela dépend de notre activité commerciale. En période calme comme avant l’été, je m’attaque à une problématique et j’en fais un article, une analyse pour essayer de démocratiser l’accès à la connaissance par la DS. Plus les gens comprendront ce que l’on fait, plus cela nous sera bénéfique car ça fait évoluer le secteur.
Quand on est en mission, je peux travailler sur l’extraction, sur l’analyse des résultats de cartographie, mais au sein de l’équipe on peut tous mener ces tâches. Je fais aussi de la formation, donc parfois la journée type, c’est aller enseigner. A l’échelle d’une semaine, je passe au minimum une journée ou deux sur le code et le développement. Une partie du travail est aussi consacrée à la veille, technologique ou sciences sociales. Sur Twitter, je suis des gens comme Mehdi Maizi, ou Mathieu Jacomy dans le domaine de la carto (Gefi), qui travaillent sur la démocratisation de la social data science.
Actuellement on passe aussi du temps à revoir nos offres pour qu’elles collent à nos évolutions techniques : il faut pouvoir expliquer au client ce qu’un nouvel algorithme, une nouvelle clusterisation peut lui permettre de comprendre sur son marché, sa communauté, et les contenus que consomme sa communauté en dehors du sien.
Pour en savoir plus sur la cartographie réalisée sur Twitch, l’émission Underscore :
Commentaires :
A lire également sur le sujet :






