
Le ML Ops – partie 4 : pour une stratégie de réutilisation des solutions

Quatrième article de notre série consacrée au Machine Learning en production et ses solutions ML Ops dans le Cloud :
- Partie 1 : Le Machine Learning en production et ses solutions ML Ops dans le Cloud
- Partie 2 : Pourquoi se lancer dans une démarche de Machine Learning
- Partie 3 : La définition d’un algorithme ML
Comme nous l’avons vu précédemment, un projet de modélisation de Machine Learning est un processus itératif où l’on peut revenir maintes fois sur les étapes préparatoires. Dans cet exercice de recherche d’un modèle, il faut se rappeler de chaque différence d’approche, lors des boucles d’exploration et de raffinement successives. Et donc, tracer tout changement.
Échecs et succès forment ainsi un condensé de savoir à mémoriser et à diffuser collectivement, car ils permettent d’éviter de tomber deux fois de suite dans le même écueil. Et de gagner en productivité, en vélocité pour le lancement d’un nouveau produit.
Effectivement, si besoin d’une solution applicative, autant capitaliser en allant juste mettre la main sur celles développées antérieurement par notre entourage.
Évoquons alors un avantage clé de l’apprentissage automatique: sa capacité à ré-employer les modèles ML d’une application à une autre si les problématiques à traiter sont concomitantes. On parle ici de transfert d’apprentissage (transfert learning).
À cela, la famille des réseaux de neurones est réputée pour sa facilité à se resservir d’un graphe dit pré-entraîné (déjà pondéré), pour en venir plus lestement à paramétrer le modèle clone. En pratique, il s’agit de figer l’ensemble des poids du modèle d’origine, excepté ceux des axones reliant entre elles les quelques dernières couches neuronales*. Le nombre de valeurs de coefficients de pondération à estimer décroît ainsi considérablement. Et les ressources computationnelles à provisionner sont par conséquent nettement amoindries.
* (Le nombre de déblocages d’axones en partant de la fin du graphe se trouve être inversement proportionnel à la similarité des sujets de modélisation.)
Ces temps-ci, les acteurs dominants du machine learning, Google Brain, Facebook AI Research, Open AI, etc., adoptent conjointement la démarche de partager en licence libre certaines technologies de pointe qu’ils développent un à un en centres de R&D. L’une des donations les plus retentissantes est le modèle Google BERT, avec ses centaines de millions de poids ayant été calculés après de longues heures d’entraînement sur une grappe d’ordinateurs à puissance totale colossale.
Et ce modèle BERT (Bidirectional Encoder Representations from Transformers) peut maintenant être importé dans un programme informatique via une ligne de commande Python on ne peut plus simple (via le hub de l’éditeur Hugging Face – voir aussi TensorFlowHub, PyTorchHub) :
import bert
Sur le même principe de dépôt partagé de fichier textuel (type GitHub) ou d’artefact binaire (type Nexus) dans le cadre des solutions logicielles 1.0, les data scientists aspirent à fédérer leurs projets, en diffusant dans un model hub les aboutissements de travaux jugés prometteurs (voir paperswithcode.com, modelhub.ai).
D’accord. Mais qu’ont-ils matériellement à partager? Et comment veiller à bien transmettre ce qui constitue l’aboutissement de leurs travaux scientifiques?
Qui conçoit, maintient après
Cette dynamique de partage avec des tiers, via une plateforme de distribution, est tout à fait salutaire. À condition que chaque contribution respecte un certain formalisme.
Résumé en trois mots: reproductibilité, documentation et portabilité.
La reproductibilité des résultats
En sortie d’une expérimentation, le code informatique, la configuration du matériel informatique et l’échantillon de données ayant permis la formation du modèle importent autant que le modèle lui-même. C’est l’association des quatre éléments qui prime finalement: code, données, modèle et configuration infrastructurelle.
Relevons qu’une partie du projet logiciel sert à (ré-)entraîner l’estimateur ML. Sachant que, quel que soit le niveau de performance du modèle obtenu en sortie, viendra tôt ou tard sa date de péremption, en raison de diverses causes que nous aborderons par la suite. La mise à disposition du code source est donc clairement bienvenue.
Pour reproduire une expérimentation ML, il est également souhaitable d’avoir connaissance de l’environnement hardware au sein duquel la tâche de formation du modèle a été exécutée: notamment, connaître l’ordre de grandeur de la mémoire-cache (pour se faire une idée du type de processeur à privilégier), ou savoir aussi si les opérations algorithmiques sont parallélisables sur une carte graphique.
L’échantillon de données, quant à lui, porte en soi les caractéristiques qui ont conduit le processus d’apprentissage machine à converger de la sorte (vers telles valeurs de paramètres du modèle).
Un livrable doit donc impérativement inclure ces quatre éléments. Ou a minima, documenter ses sources.
La documentation du projet
La documentation est un remède contre la perte de connaissances clés. À ne surtout pas négliger. Ni concernant le code, ni le modèle, ni les données, ni les configurations hardware.
En parlant de documentation, venons-en au dilemme des quelques années passées. Une fraction non négligeable de numériciens (celle fraîchement sortie de formation académique, particulièrement) n’est pas vraiment préoccupée par les problématiques opérationnelles*. Sa vocation tient plutôt à l’envie de mener des expériences sur un tas de données dans un serveur de notebooks.
* (Fonctionnement du service dans le système de production, tenant compte des contraintes techniques existantes.)
Un notebook est un document édité dans un environnement de développement web basé client (Jupyter, Zeppelin, Polynote, ou autres), dans lequel l’utilisateur est invité à remplir une succession de cellules: avec du code (Julia, Python, R, Scala, etc.), ou du texte (Markdown, HTML), selon ses intentions. Cette invention permet d’avoir une approche interactive dans son travail, par une compilation immédiate du contenu de la cellule.
Le notebook a été conçu dans l’idée de permettre aux data scientists de restituer des rapports de synthèse de leurs sujets en cours. En alliant programmation, résultats d’opérations et commentaires. L’interface est tout à fait adaptée pour faire une soutenance d’avancement, d’autant qu’elle permet la publication de graphiques associés aux données concernées dans l’étude.
Or, certains data scientists travaillent exclusivement dans des environnements notebook. Et ce support leur sert d’archive de leurs travaux. Le souci est que cet outil n’a pas été pensé initialement pour permettre la bascule des segments de code éparpillés dans le document vers un environnement de production. Le notebook avait alors pour fonction d’être un brouillon, ou au mieux un support bien présenté.
Le projet a beau être documenté, au travers d’illustrations dans ces notebooks, quand vient le temps de passer le logiciel dans un processus d’industrialisation, tout un tas de questions techniques se posent.
La portabilité de l’application.
“Ce n’est pas mon affaire, le prototype fonctionne dans mon notebook.” pourrait-on entendre de la part de data scientists peu scrupuleux envers leurs collègues chargés d’industrialiser le service. Cela étant, alors que le contenu du logiciel est bel et bien en vrac 😬.
Le notebook est littéralement un bloc-note. Sa pratique peut innocemment induire des abus. Comme sauvegarder le document avec le nom “Untitled 12-final (copy)(1).ipynb”. Ce qui est franchement incompatible avec l’idée d’un transfert de propriété (du concepteur vers le mainteneur).
Son utilisation n’incite pas à recourir aux bonnes pratiques de développement logiciel : telles que la programmation modulaire, l’abstraction, ou la virtualisation de l’environnement de travail.
Il s’agit pourtant, avec la programmation modulaire et l’abstraction, de favoriser l’imbrication de services tiers dans sa solution. De manière à s’appuyer sur les contributions d’autrui, dans l’idée de ne pas avoir à réinventer la roue.
La virtualisation permet d’isoler l’environnement du projet, de rassembler dans une liste l’ensemble de ses dépendances, dans le but d’en faciliter la portabilité. Cela permet ensuite à quiconque d’opérer le téléchargement et l’installation des prérequis sans embûche. Afin de bénéficier des services de l’application, sans avoir à faire appel à l’aide d’un administrateur système.
S’impose, en fin de compte, le recours à la culture DevOps.
Du fait de pratiques hasardeuses (voire périlleuses) lors du déroulement d’un projet de ML, celui-ci est mis à risque de n’aboutir sur aucun livrable probant. Le chantier est encore assez souvent arrêté en raison d’un manque d’anticipation de la complexité du flux logistique correspondant au service attendu.
Et le DevOps inculque aux développeurs de logiciel la philosophie :
You build it, you run it.
Songez à la maintenabilité de ce que vous allez livrer.
Que définit ce terme “maintenabilité”, spécialement en ce qui concerne un projet de ML? On peut dire que ce mot englobe les pratiques qui visent à stabiliser l’application. Par des techniques DevOps d’automatisation et d’observabilité, de bout en bout de la chaîne de production.
Comme un besoin de plateforme DevOps
En 2015, une équipe d’ingénieurs de Google a dressé un constat sur le déficit technique latent au sein de ses systèmes d’apprentissage machine. Leur publication a eu un écho retentissant dans la communauté data science, en levant un tabou sur les facteurs de risque que présente l’adoption à grande échelle d’une telle innovation.
Le papier évoque à juste titre les difficultés à maintenir une plateforme de déploiement de services ML, dans son contexte particulier de traitement intensif de flux de données. Il commence par souligner le caractère pluridisciplinaire de la spécialité, qui fait littéralement figure de croisement entre ingénierie dédiée à l’orchestration de machines virtuelles et gestion opérationnelle de l’ensemble de ces flux de données à exploiter.
L’équipe de Google vise à sensibiliser les esprits en exposant un schéma d’architecture de production avec en miniature la tâche de conception du modèle, face aux tâches techniques subsidiaires. Cette figure cherche à mettre l’accent sur l’importance des problèmes transverses, liés à l’acheminement des data, à l’exposition du service, et à la supervision des performances.
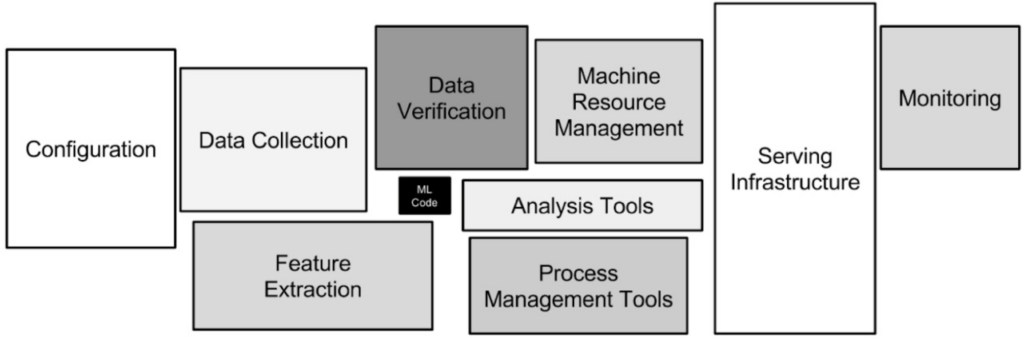
source: Hidden Technical Debt in Machine Learning Systems
Pour une entreprise avec des ambitions de lancement à moyenne ou grande échelle, le message à retenir ici est qu’il n’y a pas de gain facile (quick-win) dans la fabrication de machines apprenantes. Les dettes techniques finiront par vous le faire payer cher, si vous choisissez de faire l’impasse sur ces chantiers systémiques.
L’enjeu est de s’investir, aussi tôt que possible, dans le design et la construction de son infrastructure dédiée au machine learning. Pour éviter d’être submergé par les chantiers à livrer des data scientists, qui a priori seront peu d’humeur à se pencher sur les couches basses de la pile (back-end stack) 😬.
Dans l’effort d’architecture de cet empilement technologique, il est déterminant de chercher à appréhender l’ensemble des risques de défaillance. Concernant la santé des sources de données essentiellement. Qu’elles soient corrompues, en retard, ou incomplètes.
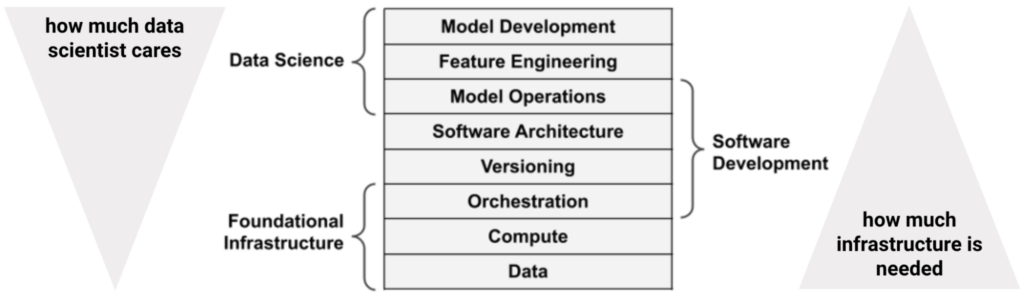
source: Effective Data Science Infrastructure, Manning, Ville Tuulos, 2021
Les ingénieurs de chez Google incitent en l’occurrence dans leur papier à se préoccuper de la distribution empirique des flux consommés par le service. Cette vue probabiliste de la répartition, comme dans le cadre de toute étude statistique, est à analyser de long en large et en travers.
En réalité, comme mentionné au début du chapitre, tous les projets de machine learning sont des projets d’édition de logiciels informatiques. À ceci près que la formule de prise de décisions du logiciel 2.0 repose intégralement sur les données fournies en entrée (data-centric software – par opposition aux designs d’architecture du logiciel 1.0, focalisés exclusivement sur le code, code-centric).
source: oreilly.com/radar/mlops-and-devops-why-data-makes-it-different
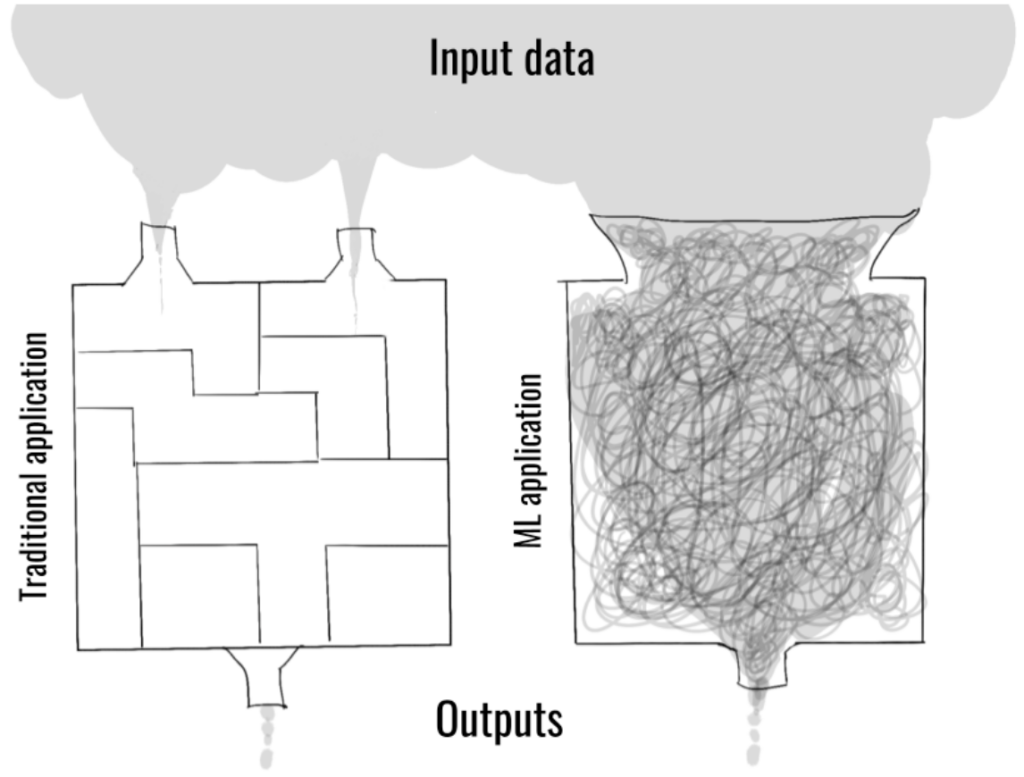
Cette boîte opaque (contrairement au logiciel 1.0, une application de ML n’associe pas systématiquement un bug à une ligne de son programme. Le dysfonctionnement peut aussi provenir de la matrice de poids du modèle. Déjouer les bugs est alors une action relativement complexe, s’il s’agit de déchiffrer les irrationalités de cette matrice.) qu’est par défaut l’application ML sera occasionnellement impactée par d’importantes distorsions (data drifts) dans les distributions statistiques des variables caractéristiques (features) dont tient compte la fonction prédictive :
- Que ce soit entre le jeu d’entraînement et les flux de données servis au modèle en environnement de production (training-serving skew).
- Ou concernant les flux de données en production, impactés par un changement de distribution significatif à travers le temps (covariate shift, label shift).
On parle alors de dette technique, dans la mesure où la distribution des estimations d’un modèle en production risque d’évoluer en déphasage par rapport à celle des relevés de la réalité terrain.
Comment se fait-il que ces histoires de distributions statistiques aient une telle incidence sur la stabilité des performances d’un modèle ?
En résumé, aux yeux des statisticiens, l’étape de collecte des données d’entraînement (jeux d’apprentissage et de validation), lors du processus de formation d’un estimateur, équivaut à un échantillonnage aléatoire de la vraie distribution des variables caractéristiques (et de la variable cible, en cas d’approche supervisée). Et comme évoqué auparavant, un modèle ML est jugé performant si son taux d’erreurs de généralisation est en-deçà d’un seuil acceptable. Cette approche par défaut de former l’estimateur avec une représentation restreinte et figée de la réalité génère un casse-tête d’un point de vue opérationnel.
Typiquement, si une fois le déploiement opéré, le flux de données de production ne fournit que des tirages de valeurs de variables caractéristiques pour lesquelles la logique de déduction du modèle ML est mise à rude épreuve (car soumise à une trop grande hétérogénéité par rapport aux exemples d’apprentissage et de validation), alors attendez-vous à ce que les performances soient plutôt erratiques, ou aient tendance à décroitre inexorablement.
Un exemple pour exposer le problème: prenons le cas d’un estimateur du prix d’un bien immobilier qui serait formé sur le concept de marge achat-vente (le cas d’usage iBuying), avec des exemples d’habitations principalement de classes énergie D-E-F-G. Alors ce modèle ML risque d’être mis en déroute par la mise en œuvre progressive de la Loi Climat, qui incite à la rénovation des logements locatifs mal isolés thermiquement (provoquant ainsi une bascule vers les classes plus sobres énergétiquement, A-B-C). Et par répercussion joue sur la dévaluation des biens immobiliers rangés en dessous de la classe C.
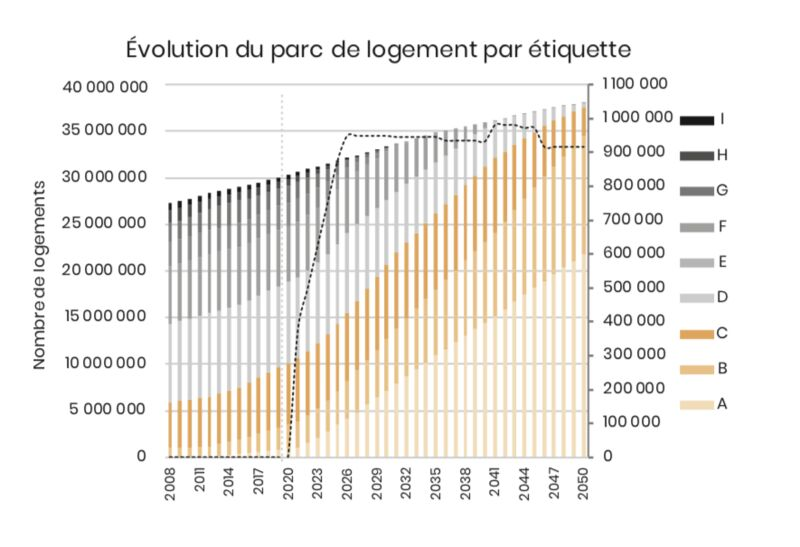
source: theshiftproject.org/crises-climat%E2%80%89-plan-de-transformation-de-leconomie-francaise
C’est ainsi. Toutefois, contrairement à l’humain qui peut adopter une posture d’esprit critique sur ses propres choix, le logiciel 2.0 est programmé pour affirmer une réponse, quoi qu’en vale la crédibilité de cette dernière. Le modèle résultant de l’apprentissage automatique ne se rendra pas compte de lui-même de la limite ou de l’obsolescence de ses connaissances (sans l’ajout d’une boucle de rétroaction).
Concrètement, avec son prisme de lecture trop terre-à-terre*, un modèle ML ne verra rien d’anormal à décider de caser un cube dans une boîte à formes strictement triangulaires ou rondes.
* Les modèles de machine learning en sont au stade de l’intelligence faible. Par opposition au concept d’intelligence forte qui elle pourrait se livrer à une interprétation globale du contexte en place.
Il y a donc besoin de temps à autre d’un ré-entraînement avec un échantillon de données davantage représentatif des véritables distributions source et cible, dans le but d’approximer à nouveau la fonction du modèle optimal inconnu.
Question maintenance, en plus de ces questions de training-serving skew, covariate shift et label shift, l’opérateur aura affaire à un problème tout autant préoccupant, dans son activité de supervision des performances du service ML. À son poste d’observation, il prend note que le phénomène à modéliser se comporte en processus non stationnaire, que le modèle optimal sur lequel s’appuie sa définition a une structure qui se déforme en fonction du temps.
Le modèle ML est un artefact qui se déprécie irrémédiablement avec le temps
La littérature spécialisée désigne cette mue par le terme de dérive conceptuelle (concept drift). De quelle magnitude parle-t-on? Voyons-voir. En pratique, le comportement du phénomène tel qu’observé dans la réalité du terrain peut dépendre d’un cycle saisonnier (été/hiver) relativement anticipable. Ou à l’extrême être complètement chamboulée par une crise (économique, météorologique, sanitaire). Remarquons qu’une dérive conceptuelle se traduit par le fait suivant: pour tâcher d’expliquer le comportement de notre variable cible, il ne fait plus sens de combiner, comme par le passé, les features utilisées. Les temps changent…
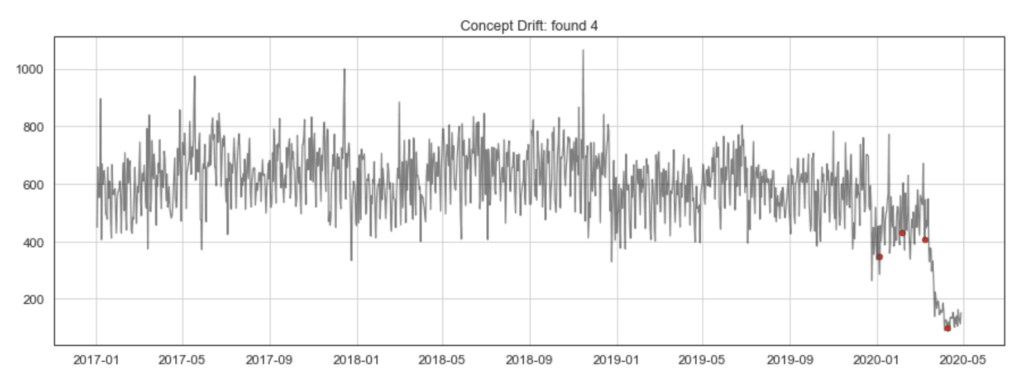
source: phdata.io/blog/the-impact-of-covid-19-on-machine-learning-models
À cet égard, nous garderons tous certainement en mémoire l’instauration de notre premier confinement national en mars 2020, due à la propagation du coronavirus-2019 sur le territoire. Cet événement a, en quelques jours, rendu caduc un nombre non négligeable de formules de prédiction sophistiquées (dans les domaines financier et énergétique, entre autres), en raison de l’impréparation de leurs concepteurs à ce scénario rocambolesque de mise en pause de l’économie mondiale.
Sur le marché du foncier, dans “le monde d’après”, le pavillon avec jardin potager loin des grandes métropoles était devenu le principal engouement. Cette tendance d’exode rural avait beau être perceptible chaque été, elle n’avait certainement pas pris autant de poids dans les critères d’achat les quelques années précédentes.
Au vu de tout ce qui vient d’être évoqué, s’il n’y avait qu’une leçon à tirer des enseignements ML Ops, la-voici : le modèle ML est un artefact qui se déprécie irrémédiablement avec le temps.
Et devant pareilles subtilités en environnement de production, l’objectif de pilotage ML Ops est clair : parvenir à lever une alerte en cas de détérioration critique des indicateurs de performance. Afin de faire appel aux bons interlocuteurs, pour déclencher immédiatement une procédure d’intervention, humaine ou automatisée, visant le rétablissement du service (avec une alternative au modèle défaillant).
Là où un rapport d’investigation permettra de surcroît a posteriori de tirer un enseignement sur les causes premières de ce comportement déviant qui a compromis la fiabilité de l’estimateur exposé.
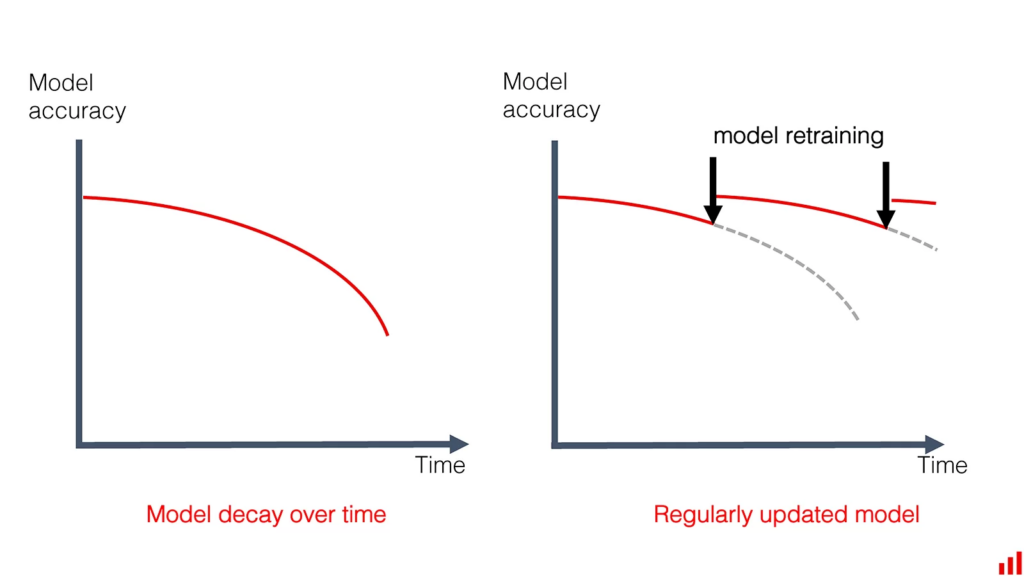
source: evidentlyai.com/blog/machine-learning-monitoring-data-and-concept-drift
Avertissons qu’un modèle en production peut sans préavis perdre sa boussole. Mentionnons que dans le pire des scénarios, en l’absence de garde-fou, votre modèle ML pourrait même totalement vriller, virer au cauchemar pour l’administrateur du système :
- prise en compte de stéréotypes dégradants portant sur les caractéristiques sociologiques d’un individu (le genre, le groupe ethnique, la classe sociale, etc.),
- profération d’injures racistes sur les réseaux sociaux,
- propos négationnistes ou anti-musulmans, sans modération…
Inutile de dire que, dans un tel jeu de hasard à quitte ou double (servir ou non un modèle opaque), nous privilégions l’option où peuvent être évités le goudron et les plumes sur la place publique…
L’engrenage Data x ML x DevOps justement permet de modérer autant que possible l’impact de dérives silencieuses, dans le cadre d’un projet applicatif. Une telle plateforme Data x ML x DevOps est censée nous apporter l’assurance que toute variation dans le code source du logiciel (ou dans les poids du modèle ML, ou dans les distributions statistiques des flux de données d’entrée) sera aussi peu susceptible que possible de causer un quelconque dysfonctionnement du service exposé.
“Mieux vaut prévenir que guérir”, comme dit l’adage.
L’action initiale en question sera révélée de manière explicite ou implicite à la lecture d’un journal d’exécution (log). Nous rechercherons primo la trace d’une intervention humaine. Ou secundo (en rapport avec le contexte Data x ML x Ops), un changement de comportement dans un phénomène retranscrit par l’un des flux de données entrants.
D’où l’intérêt de suivre à la loupe quelques bonnes métriques, dans des systèmes de monitoring classiques type Prometheus+Grafana, la suite Elastic, Splunk… Ou davantage spécialisés dans les sujets de fond ML/DataOps, type Evidently AI, Fiddler, Alibi, Monte Carlo Data…
D’autre part, la mise en place d’un processus automatique de formation et de livraison de modèles nous apparaît maintenant comme un impératif. Ayant été prévenus que la logique d’un modèle (logiciel 2.0) est fugace, celle d’une séquence d’instructions ordonnancée (logiciel 1.0) est résiliente.
Dans notre prochain article : Machine Learning et livraison continue, triple boucle infinie…
Commentaires :
A lire également sur le sujet :






