
Retour sur Dataquitaine 2023 : IA, recherche opérationnelle et Data Science

Le 02 mars 2023 à Bordeaux a eu lieu la 6ème édition de Dataquitaine. Des centaines d’intéressés se sont déplacés pour échanger sur leur avancée entre termes d’IA, de recherche opérationnelle et d’optimisation. Vous trouverez dans cet article une vue globale des différentes présentations auxquelles j’ai eu le plaisir d’assister. Pour les thématiques avec lesquelles j’ai eu le plus d’affinité, j’ai pris le temps de compléter le résumé de la présentation avec des informations n’ayant pas été évoquées à l’oral.
J’espère que cet avant-goût de Dataquitaine vous donnera envie de vous y rendre l’année prochaine !
En mise en bouche, je souhaite souligner la diversité des sujets traités, d’une présentation presque métaphysique où Axel Palaude (INRIA) nous a expliqué sa problématique de thèse “la modélisation du processus et les différentes étapes de l’apprentissage humain pour un problème ouvert de catégorie créative”, au témoignage de Joanna Morais (Avisia), qui a détaillé comment ils œuvrent pour aider les associations à passer à l’échelle techniquement, notamment pour atteindre une maturité de plateforme data plus pérenne. Adieu les fichiers excels n’existant que sur un vieux PC sans aucun backup.
Abordons maintenant, les diverses présentations auxquelles j’ai pu assister.
LocalSolver Studio : développer et déployer une app d’optimisation en quelques clics
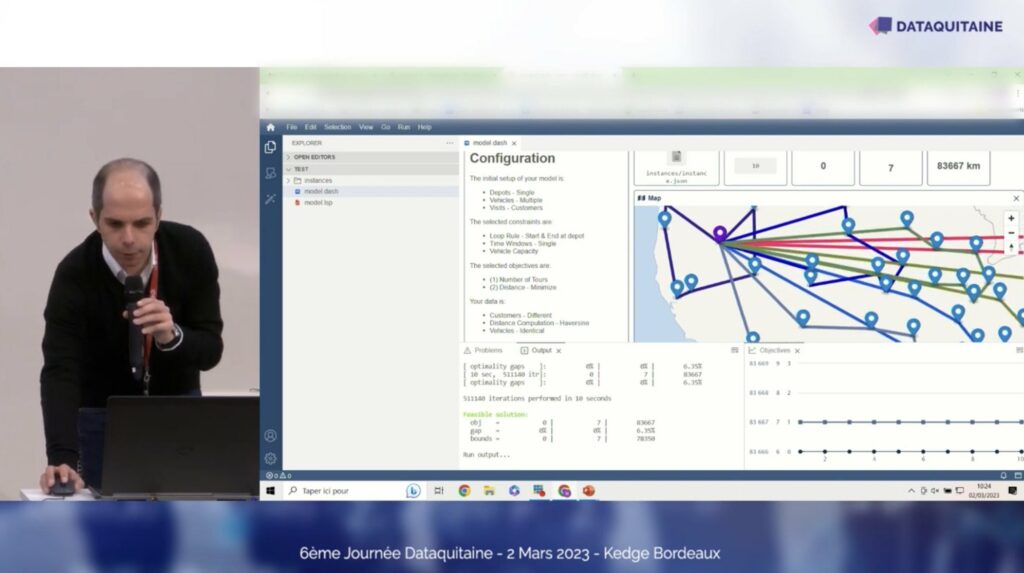
Julien Darley (LocalSolver) a présenté une application de recherche opérationnelle permettant de résoudre des problèmes d’optimisation sous contrainte. Par exemple, établir les trajets des camions de livraisons de produits frais pour différents magasins en partant d’un même lieu de stockage, ayant une contrainte de poids sur le chargement des camions, des contraintes horaires, et nombre de camions maximum.
Deux versions sont disponibles, une qui peut tourner en local et une autre qui effectue ses calculs dans le cloud sur un serveur de LocalSolver. C’est très intéressant de savoir que ce type d’outil existe et mieux encore, qu’il est facile à prendre en main afin d’être utilisable par des data scientists (ou des programmeurs) novices en Recherche Opérationnelle.
En effet, avec un algorithme de Machine Learning, il est possible de prédire le stock nécessaire d’une multitude de magasins. Mais c’est bien beau de savoir qu’on a besoin de X produits dans tel magasin, l’étape suivante consiste à pouvoir utiliser ces informations pour planifier le réapprovisionnement des stocks en conséquence. C’est à ce moment que peut intervenir LocalSolver dans une pipeline de Machine Learning.
Il prend en entrée les prédictions des modèles pour planifier le meilleur parcours, le meilleur agencement de camions, etc.. Il ne s’agit que d’un exemple parmi d’autres problèmes de Recherche Opérationnelle, mais ça fait plaisir de voir le lien qu’il existe avec le domaine du Machine Learning.
BNP : Détection de la fraude basée sur l’intelligence artificielle et les bases de données orientées graphes
Lors d’un POC évaluant la probabilité qu’un client puisse rembourser un micro-crédit, l’équipe Data a utilisé un graphe pour améliorer les performances du modèle. A l’aide de Neo4J (un système de gestion de bases de données), ils ont modélisé les interactions entre les différents clients souhaitant souscrire à un prêt.
De par leur base de données labellisés, ils ont pu extraire des features (variable alimentant un modèle de Machine Learning) intéressantes depuis le graphe généré pour pouvoir alimenter leur modèle. Pas moins de 300 features ont été extraites du graphe généré. Toutes ne sont évidemment pas pertinentes d’après le modèle, mais on voit tout l’intérêt de générer un graphe pour modéliser les interactions inter-comptes ou les interactions au sein d’une même session de connexion.
Un fait que j’ai trouvé remarquable sur ce projet, est la possibilité de mesurer les performances de ce nouveau modèle. En effet, comment mesurer le taux de fraude détecté via l’algorithme si on ne propose jamais la possibilité de faire du micro-crédit aux fraudeurs potentiels ? On ne saura alors jamais s’ils allaient frauder ou non.
Pour réussir à mesurer les performances de leur modèle, un système d’AB-testing a été mis en place. Une partie des fraudeurs potentiels (le groupe A) n’a pas eu la possibilité de faire un micro-crédit, tandis que l’autre partie des fraudeurs potentiels (le groupe B) a eu la possibilité de le faire. Ainsi en monitorant le taux de fraude dans le groupe B, il est possible d’extrapoler en supposant qu’on a empêché le même taux de fraudeur dans le groupe A. On se retrouve dans le paradoxe où d’une part on ne souhaite absolument pas proposer la possibilité de faire un micro-crédit aux fraudeurs potentiels car c’est tout à fait contraire aux intérêts de la banque. Mais d’un autre côté, on a besoin de vérifier les performances de l’algorithme pour savoir si l’on n’est pas juste en train de retirer cette option à des personnes tout à fait légitime. Ce qui a pour conséquence de nuire aux intérêts de la banque (on perd des clients potentiels) et de pouvoir générer de la frustration auprès de certains utilisateurs (ils ne peuvent pas faire de micro-crédit).
Dans une perspective data driven, il est également primordial d’avoir la capacité de monitorer les performances de l’algorithme afin de détecter toute baisse impromptue de la qualité des prédictions. Ce qui doit engendrer une investigation pour savoir d’où le problème vient et si le modèle a besoin d’être ré-entraîné.
Les enjeux de l’IA Green en embarqué
N’étant pas un fin connaisseur du monde de l’embarqué, j’appréhendais de ne pas réussir à comprendre tous les tenants et aboutissant de cette présentation. Ce ne fut pas du tout le cas, Ilona-Marie Lemaire-Lefebvre (Thales) a axé sa présentation pour emmener les néophytes avec elle. J’ai pu découvrir la différence entre le “cloud computing” et le “Edge computing”.
Avec le cloud computing, on récupère et centralise les données de chacun des capteurs IOT dans un même lieu pour ensuite pouvoir effectuer les calculs. Ceci permet d’avoir toutes les données à disposition (pour faire des agrégations par exemple). En revanche, pour le “Edge computing”, les capteurs IOT ont une certaine puissance de calcul leur permettant de commencer à prétraiter la donnée. Ceci a l’avantage de réduire le flux de données à transporter vers le “nœud commun” où le traitement final aura lieu. Toutefois, le capteur ne dispose que de ses propres informations pour effectuer les calculs, il n’a pas la vision globale mise à disposition par les autres capteurs.
L’existence du paradoxe de l’IA embarquée a été mise en avant. Du côté de la Data Science, on veut le maximum de données et on dispose de ressources quasi illimitées pour rechercher les meilleures performances. Alors que du côté de l’embarqué les ressources sont très limitées. Ce qui conduit au compromis ressources/performance, on va chercher à maximiser les performances avec ce que les puissances de calculs que les ressources de l’embarqué proposent.
Pour y arriver deux stratégies peuvent alors être établies :
- Réduire la taille du modèle, et distiller les connaissances du modèles
- Spécialiser le modèle sur un problème très précis
DataGalaxy: Cataloguer son modern data stack et en faire profiter ses équipes de Data Science
De par la complexité des systèmes transactionnels et de leur stockage associé, il faut pouvoir s’y retrouver. Pour cela, un data catalogue vous sera bien utile. Il vous permettra de faire l’inventaire des données, de documenter leur provenance ainsi que la définition qui leur est associée. Ceci facilitera l’exposition et le partage de vos données à d’autres entités/services et aidera les équipes de Data Analyst / Data Science à identifier les bons jeux de données.
DataGalaxy aborde le concept intéressant de Data People Flywheel (lien ici). Les “Data People” représentent les personnes interagissant avec les données : l’expert business connaissant la donnée, l’expert technique interagissant avec la donnée, le data gouverneur propriétaire de la donnée et le data manager qui applique les directives de la gouvernance aux données de son périmètre et promeut l’autonomie des équipes data.
Sans surprise, on retrouve la gouvernance au centre de la Data People Flywheel. Chaque catégorie des Data People est en partie responsable de chaque étape de la Flywheel. La coopération est primordiale pour s’accorder et assurer une qualité d’utilisation des données optimales dans le temps.
Inspiré de la Flywheel d’Amazon (lien medium), Devoteam Revolve s’appuie également sur une Flywheel pour maximiser sa croissance en faisant grandir les connaissances de ses collaborateurs de l’entreprise.
Pour plus d’infos sur la flywheel de Devoteam Revolve, il existe un hors série reBirth téléchargeable gratuitement (ici https://revolve.team/rebirth).
Zero/few shot learning pour le NLU (Natural Language Understanding) en français
Des données, nous en avons en quantité faramineuse. Par contre des données labellisées, c’est-à-dire une description humainement compréhensible de ces données, cela se fait plus rare. Ce problème est fréquent en Machine Learning et influe directement sur les performances du modèle.
Afin de pallier ce problème des méthodologies d’apprentissage, des modèles de machine learning tel que le Zero et few shot learning ont fait leur apparition notamment dans le domaine du NLU (Natural Language Understanding). Si l’on essaie de leur donner une définition, on pourrait dire :
Le Zero shot learning (ZSL) est une forme généralisation de l’apprentissage qui vise à prédire une classe n’ayant jamais été vue dans la base d’apprentissage du modèle à partir d’informations supplémentaires. Plus concrètement, en reprenant l’exemple donné dans wikipédia (lien wikipédia), un modèle ayant été entraîné à reconnaître des chevaux sur des images, ainsi que les concepts de rayures et couleurs. Bien qu’il n’ait jamais vu de zèbre dans ses données d’entraînement, le modèle peut quand même réussir à reconnaître un zèbre, si on lui donne l’information que les zèbres ressemblent à des chevaux rayés de couleur noir et blanche (voir image).
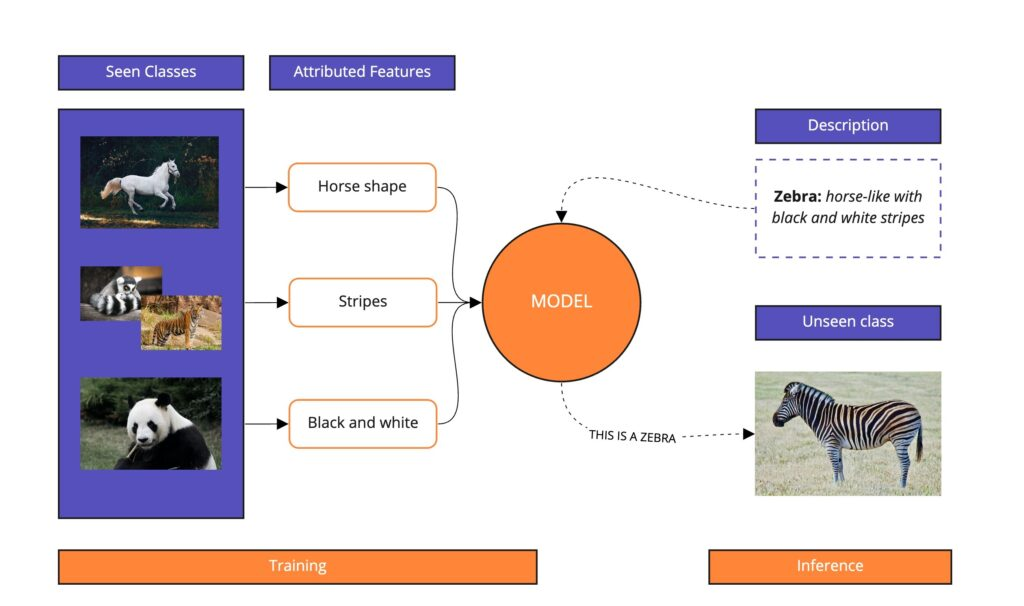
Source de l’image: https://modulai.io/blog/zero-shot-learning-in-nlp/
Le Zero shot learning consiste utiliser le modèle pour prédire quelque chose pour lequel il n’a pas été explicitement entraîné. Ce qui en l’appliquant au domaine du NLU permet la traduction de texte en différentes langues sans avoir explicitement entraîné le modèle à faire ça.
Le Few Shot Learning a le même principe de fonctionnement que le Zéro Shot, toutefois il possède quelques exemples pour guider le modèle. Si on reprend l’exemple de l’image ci-dessus, il aurait quelques images de zèbres pour guider le modèle.
Si on revient sur le domaine du NLU, la plupart des modèles sont entraînés sur la langue anglaise tel que le fameux BART de Facebook. Toutefois, une génération de modèles spécialisés sur la langue française se sont développés. Des dérivés de BART aux noms forts sympathiques, tel que BARThez (conçu pour des tâches génératives tel que la création de résumé), ou encore CamemBERT qui a été conçu sur le concept de questions-réponses, ou pour finir FlauBERT.
Container inspection automation: a proof of concept
La présentation concerne l’utilisation de IA dans l’inspection des conteneurs maritimes. Il s’agit d’un enjeu logistique majeur puisqu’il nécessite des ressources considérables en temps et en ressources humaines. Il existe plus de 100 types de défauts possibles et l’inspection d’un conteneur peut prendre entre 5 minutes (aucun défaut) et 40 minutes (défauts graves).
La catégorisation des différents défauts nécessite un haut niveau d’expertise, il a donc été réalisé par des personnes dont l’inspection des conteneurs est le métier. Je rappelle que l’étiquetage des images est une condition sine qua none à la réussite du projet. Ces images vont permettre d’entraîner le modèle de détection de défauts.
Le projet étant encore au stade d’un POC (Proof of Concept), le modèle de détection s’est concentré sur 5 types de défauts pour commencer. Pour l’instant, les résultats semblent prometteurs quand il existe suffisamment d’images étiquetées pour ce défaut particulier. En effet, l’accuracy varie entre 25% et 70% suivant le type défaut.
Pour les plus curieux, le modèle utilisé est un YOLO v5 de taille moyenne pré-entraînée sur le jeu de données COCO avec une augmentation des données.
Détection de la dérive dans un contexte non supervisé
Le but premier de la détection de dérive des données est de savoir quand réentraîner le modèle afin que ses performances soient toujours au top.
Les origines des dérives peuvent être diverses:
- L’évolution naturelle des données dans le temps : les données du passé ne reflètent pas indéfiniment le présent et le futur.
- Ce qui peut se produire au fil de l’eau (une croissance classique)
- Ou au contraire être brutale (par exemple le Covid, qui a redéfini nos habitudes en quelques semaines/mois seulement)
- Des erreurs peuvent apparaître dans les données : un capteur défectueux, un problème d’encodage, une mise à jour logiciel, etc. Les possibilités sont multiples.
Maintenant que l’on sait d’où peuvent prévenir ces dérives, il faut réussir à distinguer les “dérives virtuelles” des “dérives réelles”. En effet, ce n’est pas parce qu’il y a une dérive que les performances du modèle vont diminuer. Si ça se trouve ce sont des features non utilisées ou ayant une très faible importance pour le modèle qui sont en train de “dériver”.
Si la dérive n’a pas d’impact sur les performances du modèle, il est inutile de réentraîner le modèle, cela engendre un coût en terme de process (la mise en production finale des modèle est généralement monitoré par un humain qui donne son feu vert), en terme financier (l’entraînement d’un modèle peut nécessiter la location d’une instance dans le Cloud ayant les ressources nécessaire à l’apprentissage) ce qui a une impact direct sur le bilan carbone du projet. Bref, réentraîner son modèle uniquement lorsque cela est nécessaire et semble être cohérent.
Pour savoir quand il s’agit du bon moment, Maxime Fuccellaro nous présente les concepts d’un Robust Drift Detector dans son article, où il détaille une méthodologie pour détecter l’apparition d’une dérive ayant un impact sur le modèle.
Un arbre de décision divise l’espace des features en régions de classe homogènes (pour les problèmes de classification binaire ou multiclasse). Ceci permet de scinder le problème global en de plus petits problèmes. Il suffit de monitorer chacune de ces régions pour savoir si une dérive est en cours. Pour cela, on monitore l’évolution de la distribution des données dans les feuilles de l’arbre de décision entre la phase d’apprentissage et la phase de prédiction. Si on constate une évolution de la distribution des classes prédites, c’est qu’une dérive est en cours.
Pour rendre la détection encore plus robuste, les différentes régions de features sont pondérées en fonction de la distribution des classes du training. Si une région est floue pour l’algorithme, on y trouvera de multiples classes (parfois, il prédit une classe, parfois une autre, mais le modèle a du mal à les différencier). A l’inverse, si la région ne comprend qu’une seule classe, alors l’algorithme est plutôt confiant. Dans ce cas, le poids donné à l’apparition d’une dérive dans cette région sera plus grande que pour une région floue pour l’algorithme.
Quand suffisamment de région détecte une dérive, alors le Robust Drift Detector lève une alerte.
Rien ne dure éternellement : améliorer les prévisions en automatisant la détection des dérives
Cette fois-ci c’est au tour de Mathworks de nous présenter sa façon de faire face aux drifts en automatisant au maximum les actions à prendre pour maintenir les données et les modèles à jour.
L’idée est de réduire au maximum la supervision d’un humain, ainsi pour résoudre les trois problématiques suivantes, ils AUTOMATISENT :
- Re-training du modèle : de l’AutoML, qui va automatiquement sélectionner les features, au préalablement créés, et entraîner le modèle avec ces dernières
- Détecter un drift : utiliser un “drift détector” pour monitorer l’apparition de drift
- Labeling : automatiser à l’aide d’un modèle physique ultra-réaliste (on est sur un exemple de maintenance prédictive)
AI4Industry 2023
J’ai découvert l’existence de AI4Industry et leur initiative consistant à rapprocher les industriels des étudiants en IA. Les entreprises proposent un cas d’usage métier que les élèves tentent de résoudre au cours d’une semaine prévue à cet effet.
C’est du win-win. L’entreprise peut rapidement tester l’apport potentiel d’une solution IA afin de savoir si ça vaut le coup de mettre des Data Scientists sur le sujet. Et d’un autre côté, les élèves sortent temporairement du monde académique pour découvrir comment ça se passe pour de vrai dans le monde industriel.
Lors de cette session, c’est un cas d’usage proposé par Lectra qui a été présenté. Les élèves ayant obtenu les meilleurs résultats sur ce cas se sont vus offrir la possibilité de prendre la parole pour nous faire découvrir leur solution.
Conclusion
C’est un véritable plaisir de refaire des conférences en présentiel où l’on peut échanger avec ses pairs. J’ai apprécié la diversité des thématiques abordées ainsi que leur niveau de technicité allant d’une première approche, au POC, en passant par des thèses et des articles de recherches. De mélanger ces savoirs si complémentaires apporte une véritable richesse. Cette mise en perspective permet de savoir où en sont les avancées techniques et la maturité des entreprises qui présentent.
La présentation de Marc Palyart (Staff Data Scientist à Malt) sur la sustainability et l’IA m’a énormément plu. Un second article de blog sera consacré plus en détail à ces thématiques d’actualité, notamment sur le questionnement des méthodes permettant de réduire son empreinte carbone dans le domaine de l’IA.
Commentaires :
A lire également sur le sujet :






