
La souveraineté dans le Cloud par le chiffrement tierce-partie – Partie 4

Rappel des articles précédents :
- La souveraineté dans le Cloud par le chiffrement tierce-partie – Partie 1
- La souveraineté dans le Cloud par le chiffrement tierce-partie – Partie 2
- La souveraineté dans le Cloud par le chiffrement tierce-partie – Partie 3
Après l’interception des clés en transit dans le précédent article, nous allons maintenant parler de l’autre problème fondamental, et insolvable, que rencontre nécessairement toute solution de chiffrement tierce-partie telle que Sovereign Keys. En l’occurrence, le problème de l’authentification.
En effet, pour qu’un système tel que Sovereign Keys fonctionne, il faut pouvoir automatiquement authentifier l’instance EC2 qui demande le déchiffrement de son secret. Sans cela, on en serait réduit à accepter toutes les demandes de déchiffrement, ou à toujours les refuser ou encore à tirer au sort ; dans tous les cas ça n’aurait aucun intérêt. Ce dont on a besoin est de pouvoir automatiquement et systématiquement vérifier l’identité de l’instance appelante pour prendre la bonne décision.
« Automatiquement » a ici son importance : l’idée derrière Sovereign Keys, c’est que la présence de cette protection soit la plus transparente possible. En particulier, on veut que les instances EC2 puissent gérer le déverrouillage de leurs volumes en toute autonomie à leur démarrage, sans intervention humaine. Cela exclut donc, par exemple, d’avoir à réaliser une intervention manuelle comme se connecter à l’instance et taper un mot de passe. Quoi qu’il y ait à faire, on veut que l’instance puisse le faire seule.
Et nous allons voir en quoi ceci est un problème insolvable.
Rappel : demande de déchiffrement
Pour rappel, nous avons vu à la fin du deuxième article la cinématique d’une demande de déchiffrement. En mode résumé à l’extrême, ça se passe comme ça :
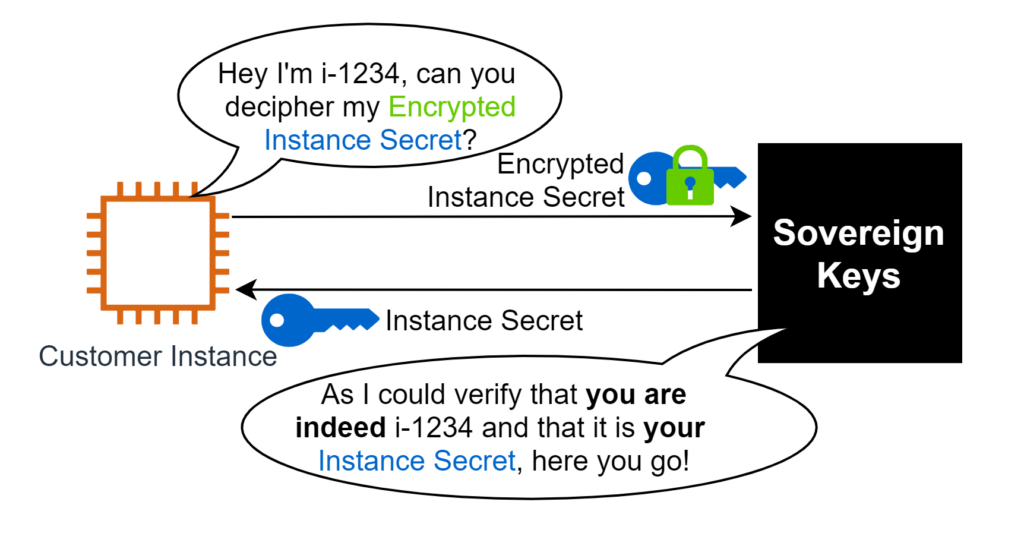
Dans le précédent article, nous avons parlé des difficultés autour de la protection de l’Instance Secret en transit. Voyons maintenant ce qu’il en est de l’authentification et de l’autorisation.
L’authentification et l’autorisation pour Sovereign Keys
Pour rappel, l’authentification (AuthN) c’est vérifier l’identité de l’instance ; l’autorisation (AuthZ) vient ensuite décider si cette instance a le droit de demander ce qu’elle demande (déchiffrer un secret par exemple). Voyons comment elles fonctionnent pour Sovereign Keys (SK).
AuthN
Pour l’authentification, c’est très simple. Lorsque l’instance envoie sa requête, elle inclut son InstanceId parmi les informations transmises. SK voit de quel VPC et quelle IP la requête vient et vérifie simplement que l’InstanceId correspond bien à une instance allumée, avec la bonne IP, dans le bon VPC.

Comme la Customer Instance peut être dans un compte AWS différent, un rôle IAM est à disposition de SK spécifiquement pour cette tâche de vérification. Ce rôle fait partie du déploiement initial à faire pour onboarder un compte AWS avec SK et permettre l’accès aux instances de ce compte.
Mais si la Customer Instance peut être dans un compte AWS différent, et donc forcément dans un VPC différent, comment SK voit l’adresse IP privée et l’ID du VPC de l’instance ? Pour comprendre, il faut revenir au schéma global. Pour communiquer avec SK (avec l’API Gateway qui fait l’authentification plus précisément), la Customer Instance utilise le VPC endpoint API Gateway (nommé “execute-api”) basé sur PrivateLink :

Et un des avantages de PrivateLink, c’est qu’il expose à la cible, ici l’API Gateway, les informations sur l’origine de la connexion, comme l’adresse IP privée et le VPC d’appartenance. Ainsi, ces informations sont visibles par la lambda chargée de l’AuthN, qui peut donc assumer le role IAM approprié et faire la vérification de correspondance VPC/IP ⇔ InstanceID.
Vous avez probablement l’intuition que ce n’est pas un très bon schéma d’AuthN ! Et la plupart du temps, cette intuition est bonne. Mais nous verrons dans la suite pourquoi c’est en fait parmi les moins pires possibles dans notre cas particulier. Pour l’instant, voyons l’autorisation.
AuthZ
En admettant que nous avons correctement authentifié la Customer Instance, il reste à déterminer si elle est autorisée à obtenir l’Instance Secret qu’elle convoite.
Pour SK, nous avons fait un choix d’implémentation : éviter autant que possible les gros machins centralisés sur le chemin critique. Genre un système d’autorisation centralisé. Il s’avère que notre cas s’y prête car on a un besoin plutôt simple : si l’Instance Secret appartient bien à la Customer Instance, on autorise, sinon on refuse. Notre problème d’AuthZ se résume donc à vérifier l’appartenance de l’Instance Secret. Et il existe un moyen simple et parfaitement inviolable de décentraliser cette information d’appartenance de l’Instance Secret : il suffit de relier cryptographiquement l’Encrypted Instance Secret à l’InstanceId.
Ça a l’air tout sauf simple dit comme ça, mais en réalité c’est une fonctionnalité native du mode de chiffrement utilisé par SK. SK utilise AES256-GCM pour chiffrer l’Instance Secret. Or, le GCM (Galois Counter Mode) est un mode de chiffrement dit “authentifié” : c’est à dire qu’en plus de rendre la donnée illisible si on ne connaît pas la clé appropriée (la base quoi), il intègre aussi un mécanisme de vérification d’intégrité qui permet de s’assurer que rien n’a été modifié avant de déchiffrer. Ce mécanisme est important en cryptographie pour se prémunir de tout un tas d’attaques potentielles mais ce n’est pas notre sujet. L’intérêt pour nous, c’est surtout que GCM permet l’ajout d’Additional Authenticated Data (AAD). Lors du chiffrement, ces AAD sont “mixées” dans le résultat du mécanisme de vérification d’intégrité, de sorte qu’on doit fournir exactement les mêmes AAD au déchiffrement pour que la vérification d’intégrité réussisse. Il nous suffit donc d’ajouter l’InstanceId dans les AAD et l’Encrypted Instance Secret est cryptographiquement lié à l’InstanceId.
Pour les plus curieux sur le fonctionnement précis de GCM, un beau schéma complet et les explications qui vont avec existent sur Wikipedia. Pour ceux qui veulent juste la big-picture dans notre contexte, la voici. On mouline l’Encrypted Instance Secret avec l’InstanceId dans les AAD en utilisant la moulinette “AES256-GCM” :

Si on fait l’opération inverse avec la même clé de chiffrement (évidemment) et les mêmes AAD, tout se passe bien :

Si on essaie de la faire avec la même clé mais des AAD différentes, ça ne marche pas :

Donc, si l’instance i-4321 entre en possession de l’Encrypted Instance Secret appartenant à l’instance i-1234 (donc créé avec i-1234 dans les AAD) et essaie de le faire déchiffrer, ça ne marchera pas :
- Soit l’instance i-4321 essaie de se faire passer pour i-1234 ; et l’authentification échouera ;
- Soit elle se présente bien comme i-4321 et donc réussit l’authentification, mais les HSMs refuseront de libérer l’Instance Secret car les AAD seront fausses.
Et ça fonctionne nativement, grâce aux bonnes propriétés d’AES-GCM !
L’impossibilité de trouver une authentification satisfaisante
Avant de revenir sur la méthode d’authentification (AuthN) utilisée par SK, parlons un peu de l’AuthN en général.
Identifier un humain
Si vous pensez à diverses techniques d’AuthN utilisées dans notre vie quotidienne, vous verrez qu’elles tombent systématiquement dans l’une ou l’autre des 2 catégories suivantes : intrinsèque ou extrinsèque.
Ce que j’appelle intrinsèque, c’est tout ce qui a trait directement à ce que vous êtes : vos empreintes digitales, votre ADN, la composition particulière de votre iris ; des “trucs” qui font partie intégrante de votre personne, qui ne peuvent pas en être séparées et qui vous identifient de manière unique. À la différence des techniques extrinsèques, des “trucs” que vous possédez ou connaissez, mais qui ne font pas partie intégrante de vous : votre passeport, vos badges d’accès ou vos mots de passe par exemple.
Une instance EC2 n’a évidemment pas de passeport, mais on peut faire la même dichotomie pour catégoriser les moyens de l’identifier.
Identifier une instance
Sans prétendre être exhaustif, voici quelques exemples de chaque catégorie pour appuyer la discussion :
| Intrinsèque | Extrinsèque |
| Instance ID Private IP + VPC PKCS7 instance identity document Pre-signed sts:GetCallerIdentity | Token Username/Password API Key Private Key + Certificate |
Compte tenu de la nature virtuelle d’une instance EC2, les éléments intrinsèques ne doivent pas être perçus comme “éternellement liés” à l’instance (au contraire de nos gènes par exemple) mais plutôt comme “indissociables et exclusifs à l’instant T” : à un moment donné, on est sûr que l’information intrinsèque est liée à l’instance et uniquement à elle. Dans le cadre d’une authentification, ça nous suffit.
C’est différent pour les éléments extrinsèques : ce ne sont que des bouts d’information copiables et déplaçables. De fait, on ne peut jamais être certain qu’une clé privée (par exemple) est connue uniquement par l’instance ; dit autrement le fait qu’une instance possède la clé ne garantie pas qu’aucune autre instance ne l’a. Dans le cadre d’une authentification, c’est un risque permanent (d’où la nécessité de faire des rotations régulières des mots de passe, clés privées, etc…).
A la vue des différents exemples ci-dessus, vous commencez peut-être à voir un “pattern” apparaître : les méthodes d’authentification intrinsèques sont toutes dépendantes d’informations fournies par AWS. De leur côté, les méthodes extrinsèques dépendent toutes d’un “secret” à stocker quelque part.

C’est parfaitement normal quand on y pense. On cherche à identifier une instance EC2, c’est-à-dire une pure construction logique que nous présente AWS. Il s’en suit que nous n’avons effectivement que deux choix :
- soit utiliser les informations qu’AWS met à notre disposition à propos de cette instance (“intrinsèque”) ;
- soit utiliser une information (une clé, un token, un password…) que nous déposons dans l’instance pour qu’elle l’utilise plus tard (“extrinsèque”).
Et dit comme ça, on voit mal comment une troisième option serait possible.
C’est là qu’arrive l’inéluctable conséquence de cette observation, les deux modes d’authentification peuvent en théorie être manipulés par le Cloud Provider :
- toutes les informations intrinsèques de notre instance, par définition, sont fournies par le Cloud Provider, on peut donc supposer qu’il est en capacité technique de manipuler ces informations ;
- toutes les informations extrinsèques devraient forcément être stockées sur un volume non protégé par SK (puisque l’authentification est un pré-requis pour récupérer l’Instance Secret) ; or si nous sommes en train de parler de SK, c’est parce qu’on fait l’hypothèse que le Cloud Provider peut lire de tels volumes et donc récupérer l’information extrinsèque qu’on utilise.
Il n’y a donc pas de solution idéale et la question devient : quelle méthode semble la “moins pire”, la plus résistante ?
Au delà de l’intuition, le bien-fondé de l’authentification utilisée par SK
Lors de la conception de SK, après avoir bien considéré le problème, il nous est apparu qu’il est probablement beaucoup plus difficile pour le Cloud Provider de manipuler une information intrinsèque que de récupérer une information extrinsèque.
En effet, récupérer une information extrinsèque, à savoir un secret quelconque stocké sur un volume non-protégé (par SK) de l’instance, ne nécessite pas de faire des hypothèses additionnelles. Si on considère l’utilisation de SK, c’est justement parce qu’on fait l’hypothèse que le Cloud Provider peut lire les volumes de nos instances à loisir (j’y reviens en conclusion). Avec une telle hypothèse de travail, il est donc logique de penser qu’un secret d’authentification stocké sur un volume n’est pas vraiment un secret.
Par contre, manipuler une information intrinsèque d’une instance nécessite une hypothèse additionnelle. Il faudrait supposer qu’AWS est capable de modifier le fonctionnement de ses API (l’API EC2 notamment) pour qu’elles renvoient de fausses informations, juste à certains moments choisis, juste pour des instances spécifiques et juste pour des clients en particulier. C’est théoriquement possible, bien sûr, mais à l’échelle à laquelle opèrent les APIs d’AWS, avec les milliards de requêtes par jour pour des millions de clients qu’elles traitent, ça paraît tout de même assez risqué et/ou coûteux à mettre en place.
C’est en s’appuyant sur ce raisonnement que nous avons décidé de concevoir l’authentification de Sovereign Keys en nous basant sur une méthode intrinsèque. Une fois cela établit, pourquoi vérifier l’association IP/VPC avec l’instance ID et pas autre chose ? Pour être tout à fait franc avec vous, avec le recul, j’aurais préféré m’appuyer sur un “presigned GetCallerIdentity” ou le “PKCS7 instance identity document” : cela aurait évité d’avoir à assumer un rôle IAM pour faire la vérification et aurait rendu l’ensemble plus simple et plus rapide. Mais on ne fait pas toujours le choix optimal dès le début et, par ailleurs, ces techniques ont leurs propres défauts, donc comme il n’y a pas d’impact sécurité notable à utiliser l’une ou l’autre, c’est resté comme ça.
Vous savez maintenant comment Sovereign Keys fait l’authentification de la Customer Instance avant de délivrer l’Instance Secret. Bien que cela paraisse hautement improbable, il reste techniquement possible pour le Cloud Provider de manipuler cette authentification. Comment pourrait-on, au moins, détecter une telle manipulation ?
La traçabilité comme seule mitigation possible
Ça devient presque un running gag, mais là encore, seule la traçabilité offre une voie de sortie. L’idée est exactement la même que dans l’article précédent : s’assurer que les demandes tracées par SK correspondent bien à un log de la Customer Instance concernée.
Il est également possible de faire une surveillance plus indirecte, en partant du principe qu’une Customer Instance n’a aucune raison de demander le déchiffrement de son Instance Secret en dehors du cadre de son démarrage. À partir de là, on peut faire la corrélation des traces SK avec les logs Cloudtrail par exemple.
Dans tous les cas, comme pour le précédent article, on ne peut que détecter a posteriori une manipulation.
Conclusion
Dans le précédent article, j’avais conclu avec un mot d’analyse de risques. J’avais mis en avant la bonne manière (selon moi) d’aborder le problème. En résumé : il n’existe pas de solution technique permettant de se protéger à 100% du Cloud Provider dès lors qu’on exécute nos applications chez lui. Mais ce n’est pas grave car le Cloud Provider n’est pas personnellement intéressé par vos données : il en est le gardien et le véritable risque est qu’il soit contraint à fournir vos données à un tiers (un État). Dans cette approche, une solution comme Sovereign Keys donne un moyen supplémentaire au Cloud Provider de protéger vos données d’injonctions extérieures.
Pour finir cette série, je veux partager mon avis personnel concernant AWS. Depuis presque 6 ans que je m’intéresse à la sécurité sur AWS, et en particulier au chiffrement, j’ai acquis la conviction qu’AWS va plus loin que n’importe quel autre Cloud Provider pour se “sortir de l’équation” et ça se voit à plusieurs niveaux.
Ça commence dès les fondations : le cloud AWS a été construit pour être un cloud dès le début ; contrairement à ses principaux concurrents qui ont pris le train en marche et transformé à la va vite leurs infrastructures existantes (oui, c’est toi que je regarde Microsoft). Les régions AWS sont aussi indépendantes les unes des autres que possible ; ce qui a toujours offert, entre autres, l’avantage de savoir dans quel pays nos applications et données résident.
Ça continue avec les services dédiés à la sécurité : AWS KMS, contrairement aux croyances populaires, ne permet à aucun employé d’utiliser les clés des clients. C’est un système extrêmement bien construit dont j’explique le fonctionnement dans cette vidéo. De plus, les accès KMS sont systématiquement tracés par Cloudtrail. De fait, lire un volume EBS chiffré avec KMS est complètement irréaliste dans le contexte de fonctionnement normal des services. On peut aller plus loin avec des features comme le Custom Key Store qui permet d’utiliser des HSMs sous notre contrôle et de se doter d’une visibilité indépendante d’AWS sur l’utilisation de nos clés, permettant ainsi de corréler les traces des HSM avec celles de Cloudtrail.
Les briques fondamentales ne sont pas en reste. Le Nitro System, dont un whitepaper a été récemment publié, est le système d’hypervision d’AWS (le truc qui découpe les serveurs physiques en instances EC2) et il rend impossible (par conception !) l’accès aux instances par des humains. Les versions les plus récentes de Nitro vont même encore plus loin et chiffrent de bout en bout les communications réseau entre les instances d’un même VPC (ou au travers d’un peering dans la même région). Ce système apporte également d’autres avantages (secure boot, chiffrement systématique de l’instance store, …) et va d’année en année toujours plus loin pour protéger les instances EC2 des clients et, de fait, les données qu’elles contiennent.
Et je passe les mesures de protection physique des datacenters, les procédures diverses simulées hebdomadairement (épisode 41 du podcast AWS en Français), etc… L’ensemble de ces mesures est régulièrement audité par divers organismes de certification, faisant d’AWS le Cloud Provider le plus certifié du monde. Et ce n’est pas volé je pense.
Je suis donc sincèrement convaincu que l’implémentation correcte des mécanismes de sécurité proposés par AWS est techniquement suffisante pour répondre à la vaste majorité de nos enjeux sur le sujet. Les solutions telles que Sovereign Keys viennent ajouter une sécurité supplémentaire à un environnement déjà extrêmement bien protégé, un peu à la manière de la grille en acier qui protège l’accès derrière l’énorme porte blindée d’un coffre fort.

C’était le dernier article à propos de Sovereign Keys. Si vous aimez jouer avec des systèmes de chiffrement (qui n’aime pas ça ?), n’oubliez pas que c’est Open Source (GitHub) et qu’une petite journée vous suffira pour explorer et mettre en pratique tout ce que j’ai détaillé au cours de cette série 🙂 J’ai aussi fait une vidéo-tuto (en anglais) pour accompagner l’installation d’un PoC. Amusez-vous bien !
Commentaires :
A lire également sur le sujet :






