
Should you use AWS Glue Crawlers?

If you ever had the project of building a Datalake in AWS, you certainly have considered using AWS Glue crawlers at some point, would it be because you read the AWS documentation, a related article or simply the StackOverflow most upvoted solution.
At Devoteam Revolve, we did too.
This article aims to describe the reasons why we increasingly advise our clients against employing AWS Glue crawlers in their Datalake infrastructures.
I. The problem
A. Why did you need glue crawlers in the first place?
AWS Glue crawlers create and update your Datalake’s tables metadata in your Glue Data Catalog. And you need that metadata in order to connect to your data using AWS Athena — a powerful SQL query engine based on Trino, formerly known as Presto. Once queryable via Athena, your data is accessible using SQL directly from the AWS console and you can also connect it to various services in order to perform data transformation, reporting or / and dashboarding operations, inside or outside AWS.
Glue Crawlers update the Glue Data Catalog with metadata, but what metadata are we precisely talking about ? So a crawler concretely does 3 things with the Glue Data Catalog :
- It creates the table with data location in S3.
- It infers the table’s schema from the existing data and potential updates of said schema.
- It discovers new partition values in the table.
So having your metadata stored in AWS Glue Data Catalog is crucial to your Datalake. Now the question is « Should you use AWS Glue Crawler to update your tables’ metadata ? »
Note : I will not address the question of schema enforcement in a Datalake, which solves the problem because by having a fixed schema for your table, you don’t need crawlers to infer it. While schema enforcement is a best practice that should definitely be your targeted procedure, answering to the question « Should you use Glue Crawlers? » by « No, just enforce your schemas » is like answering to « How can I fix my bicycle? » by saying « Just buy a car« : it doesn’t help.
First, I will answer a corollary question to establish it once and for all : Do you have to use AWS Glue Crawler to update the Glue Data Catalog ? The response is no. There are plenty of ways to do so without using them.
But why not using Glue Crawlers ? I mean, if they do the job well there is really no reason not to use them, right ?
Well, not quite. Upon implementation and exploitation in our clients’ Data Platforms, Glue crawlers were revealed to have several flaws.
B. Glue Crawlers flaws
- Glue crawlers are expensive
Firstly, Glue crawlers are expensive. Usage at scale will not go unnoticed on your AWS bill if they are at the centre of your Datalake’s architecture. Because of the rather esoteric pricing method ($0.44 per DPU-Hour, billed per second, with a 10-minute minimum per crawler run (source)) which makes a prior evaluation of usage costs difficult, you will not see the problem until your Datalake starts to scale and the costs go through the roof. By then a comeback is obviously possible but in no way easy to perform.
- Glue crawlers are not event-driven
Secondly, glue crawlers must be triggered periodically, so they are by essence not event-driven, which introduces latency in your data. Not running them often enough exposes you to the risk of having stale data. So you would want to trigger them as often as possible. But remember : they are expensive. You start to see the pickle, don’t you ? You could trigger a crawler each time a file is uploaded in your Datalake to make it somehow event-driven, but it would be really expensive.
- Glue crawlers are approximative
Thirdly, they can sometimes be approximative, especially when dealing with csv or json file formats. At the very least, they will frequently need tweaking using glue crawler custom classifiers – a mechanism allowing you to specify how crawlers should parse your data using specific patterns – in order to get your schemas right. Hell, if you need to code something to make it work you might as well want to use a mainstream programming language, don’t you think ?
- Glue crawlers make error management difficult
And last, but certainly not least, the crawlers make any elaborate error management difficult. You have multiple options to make your crawler handle schema changes (deprecate your table, update the schema silently, fail, …), but you often want to be more precise on the behaviour of your Datalake in those situations (trigger a notification, analyse if the schema change is a breaking one, delete or simply annotate the rows with defective schema, …).
II. The alternative
A. The data architecture bit
With Glue crawlers, your architecture is only composed of an S3 bucket. You upload your file, trigger a crawler (or schedule it to trigger itself periodically) and your data is available for consumption in Athena.
Giving up crawlers by implementing an event-driven approach demands a slightly more elaborate architecture : you need an ingestion layer.
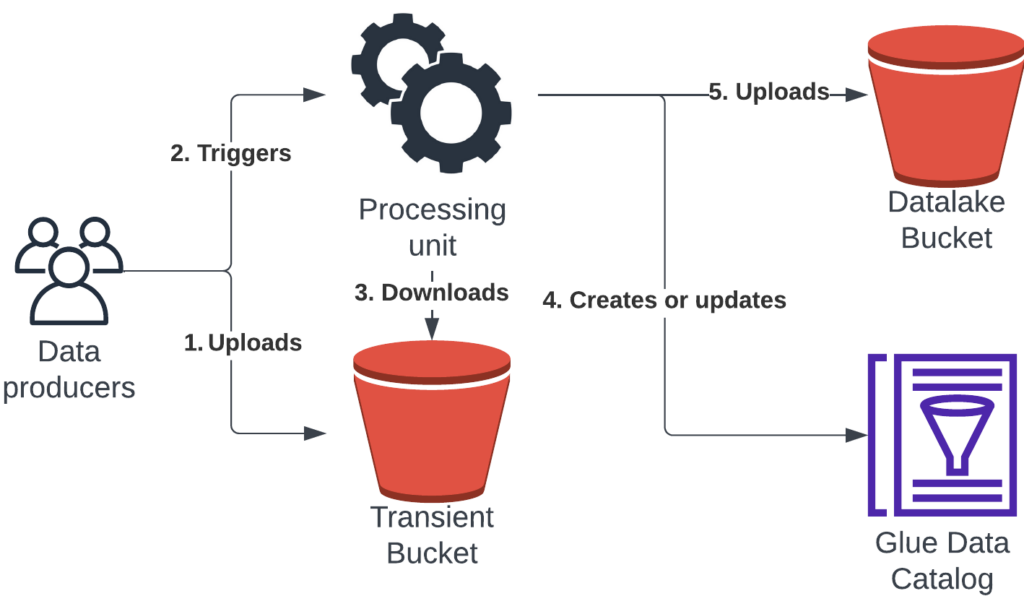
Ingestion layer process :
- The data producer uploads data in a transient s3 bucket
- The data producer triggers a processing unit which will perform the ingestion
- The processing unit downloads the data from the transient layer
- The processing unit creates or updates the table metadata in the Glue Data Catalog
- The processing unit uploads the data in the Datalake S3 bucket
This framework accommodates both PUSH (producer-driven uploads) and PULL (direct extraction from the producer’s environment) ingestion patterns. The choice of processing unit hinges on data volume considerations, with options ranging from AWS Lambda to Glue jobs or EMR Serverless applications.
This architecture is applicable in virtually every scenario, would it be an external partner pushing data, you pulling data from an external partner, data being produced by you on a periodic basis, or even data being pushed for a one-off « experiment ».
B. The technical tools
You have multiple technical tools available to implement your ingestion layer. I will now present two of them :
1. Spark
Spark is a distributed framework allowing you to execute code at scale. If the volume of your ingested data demands such scale, Spark offers schema-on-read capability, which allows you to read the data you want to ingest, infer its schema and automatically update the Glue Data Catalog with new metadata as it is stored in your Datalake.
from pyspark.sql import SparkSession
def ingest_file(
input_file_s3_key: str,
target_database_name: str,
target_table_name: str,
ingestion_mode: str):
"""
Function allowing you to read a csv file (which could easily be a json or parquet file if you adapt this code a little bit) from a transient s3 bucket, and to store it in your datalake after creating the table with the proper schema in the Glue Data Catalog if it does not already exist.
Ingestion mode (only relevant if the table already exists) can be "append" or "overwrite".
"""
spark_session = (
SparkSession
.builder
.getOrCreate()
)
input_dataframe = spark_session.read.option("header", True).csv(input_file_s3_key)
spark_session.sql(
f"CREATE DATABASE IF NOT EXISTS {target_database_name} LOCATION 's3://datalake-s3-bucket-name/{target_database_name}/'")
input_dataframe.write.mode(ingestion_mode).saveAsTable(
f"{target_database_name}.{target_table_name}",
format="parquet",
location=f"s3a://datalake-s3-bucket-name/{target_database_name}/{target_table_name}/")Note: despite not being implemented here, you can specify partition keys to be used to optimise table usage.
Using Spark in your ingestion layer also allows you to use the latest managed table format (Iceberg, Hudi or Delta) to further enhance your Datalake abilities.
2. AWS SDK for pandas
When you do not need to scale (not everyone is using Big Data out there) or you do not have spark competencies in your team (or even if you want to go for an often cheaper option), you can turn to plain native python using AWS SDK for pandas (previously known as AWSWrangler). This python library offers more or less the same possibilities as Spark, minus the ability to scale.
import awswrangler as wr
def ingest_file(
input_file_s3_key: str,
target_database_name: str,
target_table_name: str,
ingestion_mode: str):
"""
Function allowing you to read a csv file (which could easily be a json or parquet file if you adapt this code a little bit) from a transient s3 bucket, and to store it in your Datalake after creating the table with the proper schema in the Glue Data Catalog if it does not already exist.
Ingestion mode (only relevant if the table already exists) can be "append", "overwrite" or "overwrite_partitions".
"""
# the input csv file must have headers in order to have dataset column names
input_dataframe = wr.s3.read_csv(
input_file_s3_key, header="infer")
wr.catalog.create_database(
target_database_name, exist_ok=True,
database_input_args={"LocationUri": f"s3://datalake-s3-bucket-name/{target_database_name}/"})
wr.s3.to_parquet(
input_dataframe,
dataset=True,
database=target_database_name,
table=target_table_name,
path=f"s3://datalake-s3-bucket-name/{target_database_name}/{target_table_name}/",
compression="snappy",
mode=ingestion_mode)Note: despite not being implemented here, you can specify partition keys to be used to optimise table usage.
C. Advantages of an ingestion layer
An ingestion layer is – reasonably – more complex to set up than crawlers, but it provides a lot of benefits.
- Cost Efficiency
You get more manageable pricing. Because you are now managing yourself the processing unit doing the ingestion, you can scale it according to your real usages, especially if you only ingest small batches of data, an AWS Lambda function would suffice.
- Event-driven capacities
You get by-essence event-driven architecture. When ingesting your data, you can infer the schema on the fly, which allows you to directly update table metadata. Thus, your data is available for query in a matter of minutes without any other actions to perform, whereas with crawlers you had to wait for the next scheduled execution. You also have capacity to make ingestions trigger other processing to refine data on-the-go, following the purest event-driven ELT architecture.
- Enhanced data quality
You get more latitude in data quality processes. Because you have a processing layer between your data producer and your Datalake, you now have capacity to reject or at least flag for review non-compliant data even before it enters your Datalake.
III. If nobody should use Glue Crawlers then why do they exist?
I did not say that nobody should use them, I said there are drawbacks and that other more flexible and not-so-complex solutions do exist.
Implementing an ingestion layer in a toy project or in a POC is something that can be tedious if you don’t already have the boilerplate code available. In such situations (need for velocity without long-term maintainability) Glue crawlers are a good fit. You can create your s3 bucket and your Glue crawler via the AWS console in a matter of minutes and start to upload your data for direct usage in Athena or whatever tool you need. Glue crawlers are also useful when you have a S3 bucket already filled with a large volume of data of which you do not know the structure, scenario which falls under the « not industrialised use-case » category.
In conclusion, the point of this article is to advise you against using them in a production Datalake. Sometimes the trade-off between ease of implementation versus run complexity is way off-balance and we do believe Glue crawlers are such an example. You would expose yourself to the risk of having to develop ad-hoc configurations in a rigid framework to make the crawlers classify correctly your data when you could just have done that with Python code for it to be more versatile, maintainable and probably cheaper.
To go further :
- AWS Athena
- Documentation AWS SDK for Pandas (AWSWrangler)
- Pyspark Tutorials
- Event-Driven architecture, by AWS
Commentaires :
A lire également sur le sujet :






