
Envoyer des millions de notifications en Serverless grâce à AWS

Dans le cadre de l’accompagnement de l’un de nos clients, nous avons maintenu et fait évoluer une solution « in-house » de gestion de notifications Serverless qui repose majoritairement sur AWS. Elle gère actuellement plus d’un million de notifications par mois, sur les canaux E-mail, SMS et Push (c’est-à-dire via l’application mobile du client).
Serverless, dans le contexte du Cloud, est une manière de déployer et d’exécuter des applications sans avoir à gérer des serveurs.
L’architecture de l’application repose sur ces services AWS :
- API Gateway : Gestion des API compatibles Serverless
- Lambda : Exécution de code Serverless AWS
- DynamoDB : Base de données NoSQL et Serverless
- EventBridge : Bus d’événement Serverless (voir ici notre article sur Eventbridge et l’observabilité)
- Pinpoint : Envoi des notifications dans plusieurs canaux différents, permet aussi la gestion et l’édition de template.
- Kinesis Data Stream : Gestion du traitement de données en temps réel, data stream est un type de ressource Kinesis qui facilite la capture, le traitement et le stockage de flux de données à n’importe quelle échelle.
- Secrets Manager : Sauvegarde chiffrée des secrets
- Systems Manager Parameter Store : Gestion de la configuration
Cet article consiste en un retour d’expérience, et a pour objectif de présenter le pourquoi et le comment de l’application ainsi que les améliorations à venir. Il présume que le lecteur est néophyte avec AWS et la conception d’applications.
Motivations de la conception d’une solution interne
AWS inclut déjà des services pour gérer des notifications, comme SES qui permet d’envoyer des emails, SNS qui permet d’envoyer des notifications variées, ou Pinpoint qui permet la gestion de campagne commerciale et de notifications transactionnelles. Il existe aussi un grand nombre d’applications tierces qui répondent à ces besoins.
Pourquoi donc avoir développé une solution interne, et pourquoi le faire sur AWS ? La réponse, comme souvent, est un ensemble de contraintes métiers et techniques.
L’équipe mobile du client a déjà implémenté une solution tierce dans l’application pour gérer les notifications de type Push. Malheureusement elle ne répondait pas à tous les besoins de la gestion des notifications du client, à savoir :
- Suivi de l’envoi de toutes les notifications.
- Gestion d’un système de “fallback”, c’est-à-dire la possibilité d’envoyer par exemple une nouvelle notification Email si la notification de base, un SMS, n’a pas été reçue par le client.
- Création de templates pour les notifications, c’est-à-dire un modèle préconçu de message qui peut contenir des variables. Par exemple, pour un SMS de confirmation de transfert : “Bonjour {{prenom}} {{nom}}, nous vous confirmons la bonne réception de votre {{commande}}”.
Par rapport à ces besoins, la solution tierce inclut seulement la gestion des templates.
En conséquence, il était nécessaire d’avoir au minimum deux applications différentes, et le client a donc décidé de construire une solution sur mesure pour mutualiser l’expérience de ses équipes internes.
Conception originelle de la solution
Lorsque notre intervention a commencé, le client avait déjà conçu des itérations de cette application. Bien que cet article n’ait pas vocation à se concentrer sur ces étapes, il est important de présenter la logique de conception.
On retrouve généralement deux types de notifications :
- Transactionnelles : informent le client final que la société a effectué une action ou obtenu une information qui le concerne, par exemple la mise à disposition d’un document, ou alors une alerte de sécurité. Techniquement, une notification transactionnelle est envoyée à une seule personne à la suite d’un événement.
- Promotionnelles : envoyées en masse dans le cadre de campagnes commerciales. Techniquement, une notification promotionnelle est envoyée en masse à une liste de personnes.
La solution actuelle gère des notifications transactionnelles. Le client a conçu une API qui est principalement Serverless et sur AWS.
Cette API est ensuite mise à disposition à des équipes internes, qui utilisent un client ID et un client secret pour s’authentifier via le flux OAuth 2.0 Client Credentials. Il s’agit d’un processus d’authentification par des machines : cette API n’est pas conçue pour être utilisée par des utilisateurs en production, uniquement des programmes.
L’architecture en elle-même se base sur le principe CQRS (Command Query Responsibility Segregation), c’est à dire un modèle qui sépare les opérations de modification des données (Command) de celles de récupération de données (Query), ce qui permet une plus grande flexibilité.
Enfin, la gestion de l’infrastructure se fait avec CloudFormation, un service AWS d’Infrastructure as Code permettant de modéliser, de provisionner et de gérer les ressources AWS grâce à des configurations JSON ou YAML.
Objectif de notre intervention
L’application mise en place par le client, bien que fonctionnelle, présentait de nombreux problèmes :
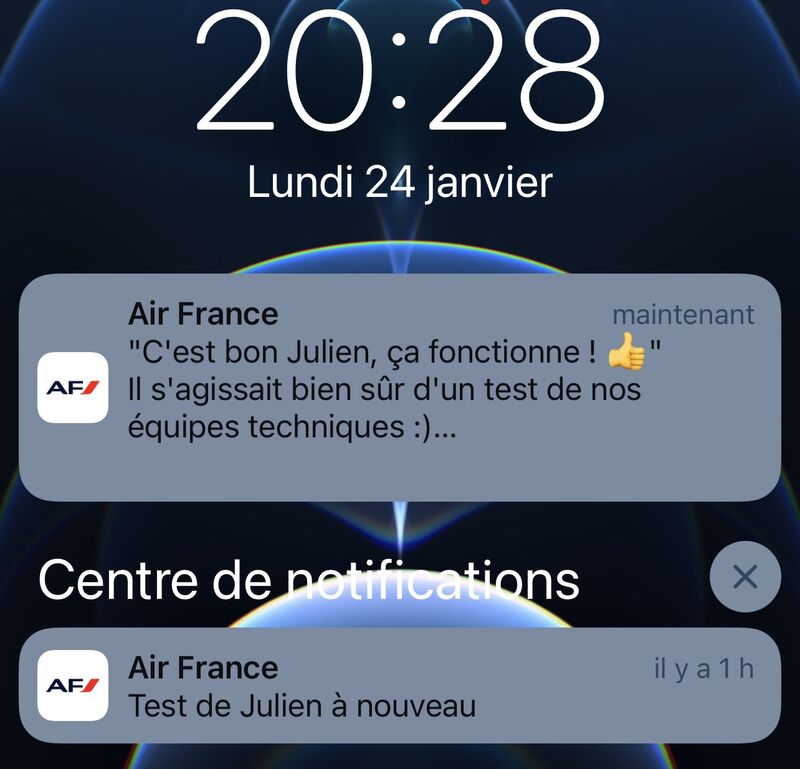
- Aucun système n’était mis en place pour les tests, qui étaient donc effectués d’une façon similaire à l’envoi réel de notification. De ce fait, il y avait un important risque qu’un client réel reçoive une notification de test. Certains d’entre vous se rappellent peut-être de la notification “Test de Julien” dans l’application Air France, en janvier 2022 (pour plus d’informations).
- Les données de l’application n’étaient pas reliées au Data Lake du client. Or, les données liées à l’envoi de notifications peuvent avoir une véritable plus-value dans l’analyse des données de l’entreprise.
- L’application présentait une certaine dette technique et le client souhaitait un refactoring afin de revoir l’ensemble d’un nouvel œil.
- L’API de l’application n’avait pas de contrat d’interface. C’est-à-dire un document qui garantit un format pour les entrées et les retours d’une API.
- Beaucoup de notifications étaient considérées comme spam, notamment au niveau des Emails.
- Le monitoring de la solution était limité à certaines métriques techniques : nombre de traitements total, traitements en erreur, latence d’exécution, etc.
Au départ, l’objectif de la mission était donc d’effectuer un important refactoring pour répondre à tous ces besoins.
Au vu de l’importance des changements, le client a décidé de concevoir une toute nouvelle application, qui reprend une partie de l’existant. Cet article va se concentrer sur cette nouvelle version, plus spécifiquement la partie Architecture Cloud. Le code applicatif, le monitoring et le lien avec le Data Dake seront eux mis de côté, avant d’éviter d’aborder trop de sujets différents dans cet article et de préserver la propriété intellectuelle du client.
Nouvelle architecture de l’application
Voici une représentation simplifiée de l’architecture mise en place :
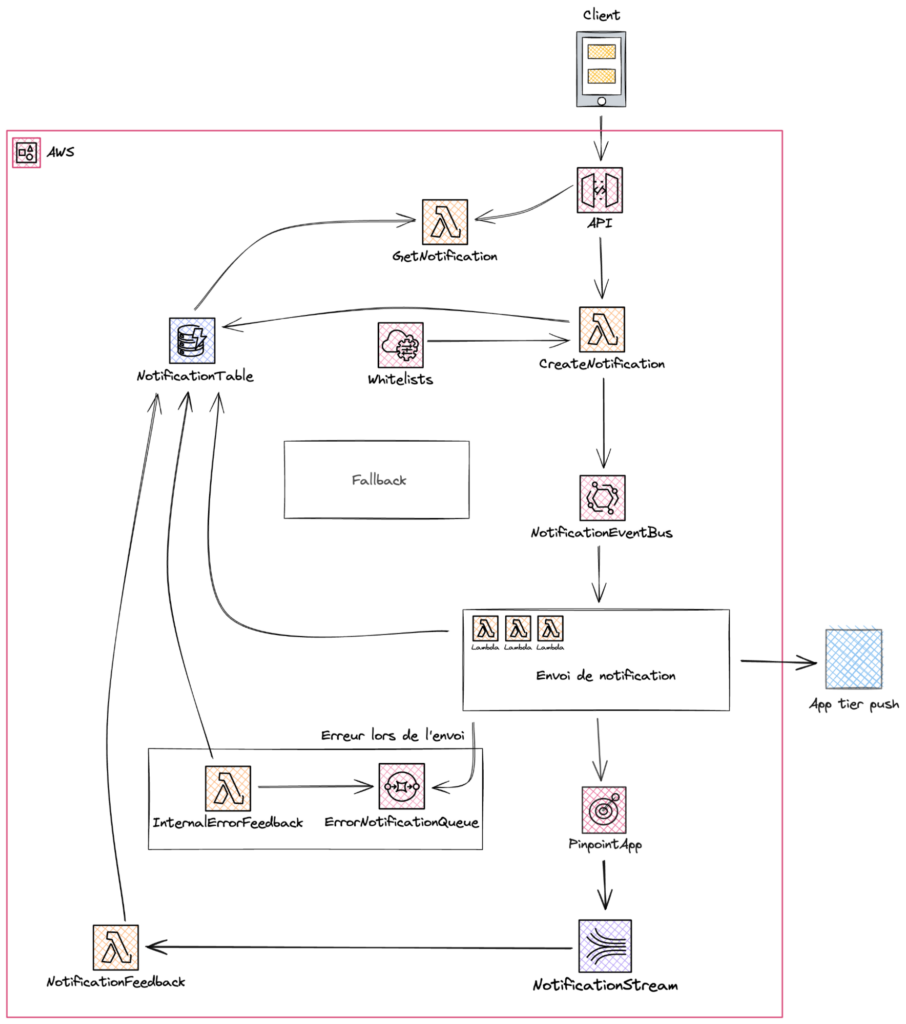
Le client fait une requête Restful vers API Gateway, qui déclenche la fonction lambda “CreateNotification”. Cette fonction valide la requête de l’utilisateur, l’écrit dans la base de données et dans le bus d’événements Event Bridge.
Ce bus permet de fonctionner de façon asynchrone : l’envoi d’une notification est une opération complexe, il n’est pas possible de confirmer directement à l’utilisateur si l’envoi effectif est un succès ou non. En cas de succès, un client a donc un code retour HTTP 200 (ce qui indique le succès de l’opération de création de notification, et non son envoi), ainsi que des données métiers comme l’identifiant de la notification. Le client peut ensuite faire une nouvelle requête pour savoir si la notification a été envoyée ou non.
Une fois qu’un événement est déposé dans le bus, une Event Rule permet de déclencher une ou plusieurs lambda selon les données dans la notification. Ces lambdas envoient la notification avec Pinpoint ou la solution tier pour les Push.
Code CloudFormation pour une règle Event Bridge (notification de type email) :
PutNotificationEventRuleEmail:
Type: AWS::Events::Rule
Properties:
Name: PutNotificationEventRuleEmail
Description: An Email Notification has been created
EventBusName: !Ref EventBusName
EventPattern:
source:
- !Ref CreateNotificationFunctionArn
- !Ref FallbackNotificationProcessorArn
detail-type:
- NotificationEventEvent
detail:
eventName:
- PutNotification
channelType:
- email
State: ENABLED
Targets:
- Arn: !Ref SendEmailFunctionArn
Id: !Ref SendEmailFunctionNameLa gestion des statuts de notification est plus complexe, c’est-à-dire : envoyé, reçu, l’utilisateur a cliqué un lien, échec, etc…
Elle est différente selon le provider :
- Pinpoint offre une intégration avec Kinesis Data Stream, où tous les changements de statuts sont envoyés.
- Bien que la solution tierce de gestion des Push offre aussi une intégration AWS (Kinesis ou S3), cette intégration nécessite un utilisateur IAM, or le client n’accepte que des rôles IAM. Nous avons donc décidé d’utiliser des webhooks à la place : c’est-à-dire une API appelée à chaque changement de statut d’une notification.
Chaque solution ayant son propre système de statut, nous avons proposé au client de les normaliser afin d’éviter toute ambiguïté.
Une fois que l’événement est récupéré, une lambda le transforme et modifie le statut de la notification dans la base de données.
En conséquence, si un utilisateur souhaite connaître le statut d’une notification, il doit faire une requête GET en utilisant un identifiant de la notification.
Sauvegarde des notifications
Les notifications sont sauvegardées en suivant les recommandations d’AWS pour versionnaliser les données dans DynamoDB. Cette logique a plusieurs avantages :
- Les données ne sont jamais modifiées, toute modification se traduit uniquement par la création d’une nouvelle ligne dans la base.
- L’historique de toute l’évolution de la notification est disponible.
La gestion du fallback
Comme expliqué précédemment, l’un des besoins principaux du client est la gestion du Fallback, c’est-à-dire l’envoi une seconde notification si la première a échoué.
À haut niveau, le fallback se base sur le statut des notifications. Si après un certain temps, une notification n’a pas un statut qui indique sa réception (la notification n’a pas encore été envoyée, elle a été envoyée mais pas reçue, elle est en erreur, etc.), une autre notification est envoyée dans un autre canal.
Tenants et isolation des tests
La nouvelle architecture est multitenant, c’est-à-dire qu’il est possible de la dupliquer afin de créer des “environnements” isolés les uns des autres, aussi appelés “tenants”. Ces tenants peuvent être appliqués à des clients ou des cas d’utilisation spécifiques.
Il est important de noter qu’un tenant est différent des environnements de type “dev”, “prod” ou similaires qui représentent des étapes dans le développement de l’application (généralement “dev” est l’environnement qui est activement travaillé par les développeurs et “prod” est l’environnement utilisé dans le monde réel). À l’inverse, tous les tenants ont la même architecture, la différence se limite aux accès et à la configuration.
Pour le moment seulement deux tenants existent :
- Live – pour l’envoi réel de notifications.
- Sandbox – pour les tests.
La configuration entre ces différents tenants inclut la notion de whitelisting. Le tenant live a sa whitelist désactivée, tandis que celui de sandbox inclut les adresses des testeurs. Il est donc impossible d’envoyer par accident une notification de test à une personne externe tant que les tenants sont bien respectés, c’est-à-dire qu’aucun test n’est effectué sur le tenant live dans l’environnement de production.
Une whitelist est simplement une liste d’adresses qui est sauvegardée dans Parameter Store.
Quant à l’architecture, nous avons utilisé des Nested Stack CloudFormation, c’est-à-dire des blocs d’architecture réutilisables (voir la documentation AWS). L’architecture spécifique aux tenants était donc dans une nested stack, et il suffisait de l’instancier pour chaque tenant :
Resources:
SandboxCore:
Type: AWS::Serverless::Application
Properties:
Location: ./core-stack.yaml
Parameters:
# Liste des paramètres pour chaque tenant
LiveCore:
Type: AWS::Serverless::Application
Properties:
Location: ./core-stack.yaml
Parameters:
# Liste des paramètres pour chaque tenantRetour d’expérience
Problèmes liés aux Tenants
Déploiement
Bien que la duplication de l’architecture au niveau code soit simple, en arrière plan, le nombre de ressources est logiquement bien plus important. Malheureusement, le temps de déploiement d’une modification dans l’architecture est proportionnel à sa complexité, et donc nous sommes rapidement arrivés à un stade où le déploiement d’une modification pouvait prendre jusqu’à une heure, avec des conséquences massives sur notre productivité.
Il a donc été décidé d’abandonner la logique de duplication totale de l’architecture. Les ressources communes aux tenants, comme celles liées au réseau, ont été déplacées dans un projet à part et sont ensuite importées dans les tenants grâce au mot clé CloudFormation import (voir la documentation AWS). Les ressources additionnelles, comme celles liées à l’archivage, sont aussi dans des projets à part. En conclusion, les tenants concernent maintenant uniquement le cœur de métier de l’application. Il a aussi été décidé que dans l’environnement de travail des développeurs, il n’existe qu’un seul tenant : live.
Ces efforts ont permis d’optimiser le déploiement, qui est passé d’un maximum 1h30 à environ 20 minutes.
Sécurité
Afin de simplifier les tests, il était initialement prévu qu’un bearer token valable en live le soit aussi en sandbox, et vice versa. Après l’utilisation de l’application, le client a émis le souhait que ce ne soit pas possible, afin de réduire le risque que le mauvais tenant soit utilisé (par exemple, des tests effectués sur le tenant de live).
La solution retenue a été d’utiliser les scopes OAuth2. Il s’agit d’un mécanisme qui permet de limiter les accès sur un token. Par exemple, un scope “email” sur un token pour une API peut garantir que les opérations se limitent à la lecture ou la modification d’emails. Dans notre situation, deux scopes sont utilisés : live et sandbox. Un token créé avec le scope “live” ne peut être utilisé sur le tenant “sandbox” et vice-versa.
Problèmes liés au templating
Comme évoqué précédemment, il existe actuellement deux providers pour l’envoi de notification : Pinpoint et l’application tierce d’envoi de notification push. Chacun possède son propre système de templating, où il est possible de créer, modifier ou supprimer un template.
Deux outils différents sont donc utilisés pour gérer le contenu des notifications, ce qui provoque des problèmes au niveau de l’expérience utilisateur, mais aussi un risque dans le contenu des templates, car ces deux applications le gèrent de façon différente.
Nous avons donc recommandé au client la mise en œuvre d’une application dédiée pour la gestion des templates.
Conclusion
Nous avons apporté des améliorations majeures à la solution d’envoi de notifications du client. Bien que cet article se concentre avant tout sur la refonte de l’infrastructure, l’architecture logicielle a été réécrite et le monitoring ainsi que l’archivage des données ont été améliorés. Ces travaux ont joué une part importante dans l’évolution du nombre de notifications envoyées par l’application, qui a doublé depuis l’année dernière.
En termes de perspectives futures, nous allons continuer la maintenance et l’évolution de l’application, la réduction de la dette technique et l’optimisation de la délivrabilité des notifications, tout en développant une application web annexe de gestion centralisée des templates.
L’équipe Devoteam Revolve vous donne rendez-vous au AWS Summit Paris le mercredi 3 avril 2024
Commentaires :
A lire également sur le sujet :






