
Machine Learning sur le Cloud : Retour sur AWS Dev Day

Démocratiser l’intelligence artificielle et le machine learning, c’est le prochain défi du Cloud AWS, et la journée du Dev Day du 11 septembre dernier était consacrée aux services AWS dédiés à ce sujet. Services managés, instances dédiées au calcul, plateforme dédiée au machine learning et à l’entraînement de modèles… l’offre d’AWS en la matière couvre une large partie des besoins, que l’on soit expert en machine learning ou non.
Durant la keynote d’ouverture, Julien Simon a passé en revue les services d’IA et de Machine Learning disponibles sur AWS :
- services applications (Amazon Rekognition, Amazon Polly, etc),
- services plates-formes (Amazon SageMaker)
- services infrastructure (Deep Learning AMI, instances GPU, etc.).
Il faut dire qu’Amazon s’est lancé très tôt dans le machine learning, avec notamment les systèmes de recommandation sur son site de vente, les robots autonomes dans les entrepôts, ou les tests de livraisons automatisée par drone. Plus récemment, nous avons vu apparaître de nouveaux services comme Alexa ou l’épicerie Amazon Go, où le checkout se fait automatiquement grâce à des caméras qui analysent le contenu du panier. Aujourd’hui, AWS ambitionne de fournir des services de machine learning qui soient opérables sans être un expert du sujet.

Services machine learning de haut niveau
On entre ensuite dans le vif du sujet avec la présentation des services de haut niveau, tous basés sur du machine learning ou du deep learning. Ces services sont accessibles à travers une API, sans nécessiter de connaissance sur le machine learning. Rekognition est un service d’analyse d’image (et de videos), qui fait de la détection de visage, de paysage et d’objets. En sortie, on récupère un document json constitué d’une liste de labels avec score de confiance (une ville, centre ville, en soirée, dock, port, etc.). Cette analyse se base sur des modèles pré-entraînés, il suffit juste de fournir une image. Concernant l’analyse de visages, Rekognition est capable de trouver leur position dans l’image, et de détecter un certain nombre d’attributs (sexe, tranche d’age, émotion, lunettes, barbe, etc.). Le service fonctionne sur un ou plusieurs visages. Jusqu’à 100 visages sont détectables, en temps réel. Parmi les applications possibles, citons l’usage d’une Fintech africaine qui utilise Rekognition dans son application mobile pour identifier ses clients pour valider certaines demandes comme un micro-crédit.
Il est aussi possible de comparer des visages, ou de rechercher des visages dans des collections. Parmi les applications possibles, la modération de contenu automatisée, ou la détection de texte dans les images (extraction de texte sur des documents structurés). Rekognition Video étend ces fonctionnalités à la vidéo, et y ajoute une dimension temporelle pour détecter l’activité (est ce que le personnage court ou tombe ?). Sky News a utilisé Rekognition Video lors du récent mariage royal pour identifier toutes les célébrités au moment de leur entrée dans l’église, en temps réel, et pour afficher des éléments de contexte et d’information.
Polly, application de text to speech (25 langues, 53 voix, en temps réel), permet de générer du contenu parlé à partir d’une chaîne de caractères. Polly dispose maintenant d’une voix française, Lea, et peut être enrichie avec un langage de balisage de synthèse vocale (SSML), pour changer l’intonation, la vitesse, créer des effets d’emphase, et rendre la voix plus naturelle. Une fonction de respiration a également été ajoutée, et celle-ci est modulable (pour marquer une pause, simuler l’essouflement, etc.).
Translate, comme son nom l’indique, est un service de traduction en temps réel, également accessible via API, qui reconnaît automatiquement le langage source, et offre à ce jour 12 paires de langages.
Transcribe est un service de speech to text, qui permet de générer un fichier texte depuis depuis un fichier son, mais pas en temps réel. Transcribe reconnaît le texte, la ponctuation, détecte les différents interlocuteurs et ajoute des timestamps. Il supporte des fichiers de bonne ou de mauvaise qualité audio, y compris la qualité téléphonique, le principal cas d’usage concernent les call center.
Enfin, Comprehend traite le langage naturel, pour extraire depuis un document les entités, personnes, lieux, noms de produits, organisations, phrases clés, etc. Comprehend détecte 100 langages, et peut analyser les sentiments (positif, négatif, neutre). Il permet aussi le topic modeling, ou la construction de groupes de documents à partir d’une collection de documents. Le Washington Post l’utilise pour créer des groupes de sujets sur ses articles (stock market, US sports, etc.).
Amazon Sagemaker
En descendant plus bas dans les couches, AWS propose aussi des services plateforme pour entraîner ses propres modèles et travailler avec ses datasets pour des besoins plus spécifiques. Néanmoins il reste fastidieux de nettoyer les données, et de monter l’infrastructure pour entraîner son IA. Sagemaker est donc conçu pour permettre aux développeurs de construire et d’entraîner leurs modèles rapidement, et de déployer à l’échelle sans avoir à gérer de serveurs. Bref, de se concentrer sur l’essentiel : la sélection de l’algorithme, la sélection des paramètres et la préparation des données. Sagemaker est constitué d’un ensemble de modules, d’algorithmes de machine learning pour démarrer rapidement, des environnements pré installés pour les grandes librairies de Deep Learning.
Retour d’expérience Blue DME
La startup Blue DME a ensuite présenté un exemple de mise en oeuvre de Sagemaker. Créée en 2015, Blue DME propose des outils de performance commerciale basés sur le Big Data et l’IA (insights sur comportement client, assistants virtuels..).
Quelques chiffres permettent de se rendre compte des volumes : 1 250 000 événements traités par jour, 8 teras de données, 20 sources de données. Blue DME fait du data processing à partir des données collectées sur les sites de ses clients. Ces données sont ensuite traitées par un Cluster Spark EMR. Comme l’explique Mohamed Ben Khemis, senior data scientist chez Blue DME, la création de valeur repose sur le fait que les modèles de machine learning aillent en production et génèrent des prédictions. Les équipes de Blue DME créent et entraînent des modèles, mais il faut rationnaliser le process de mise en production de ces modèles.

BlueDME a donc commencé par définir le cycle de vie de ses données jusqu’à l’entraînement et la mise en production du modèle, puis a développé dans un premier temps une solution en interne, « Booster ». Néanmoins, de nombreux besoins ne sont pas encore adressés : la transition entre les étapes du cycle de vie, le dimensionnement des notebooks, la gestion de la sécurité et des sauvegarde des notebooks des datascientists, les connecteurs de données, la gestion des dépendances des librairies, etc.
Blue DME a choisi d’utiliser S3 ou Redshift pour le stockage de ses données, et de sauvegarder ses notebooks sur EFS, ce qui permet de ne pas perdre le code quand la machine est éteinte. En 2018, la start-up passe sur Sagemaker. L’objectif est d’accélérer les mises en production et de changer les usages sur chacune des étapes du cycle de vie vu précédemment. D’autres possibilités intéressent les data-scientist de Blue DME, comme celle de pouvoir faire des prédictions en temps réel plutôt que par lot, ou d’avoir des modèles sur mesure. Blue DME utilise maintenant Sagemaker pour l’entraînement de ses modèles et les prédictions, et l’intégration dans le cycle de vie de la data s’est faite avec souplesse. L’intégration par défaut du monitoring dans le SDK a également convaincu les équipes de Blue DME. En termes de bénéfices, les gains de temps sont assez spectaculaires puisque le déploiement des modèles se fait maintenant en quelques jours avec Sagemaker, contre plusieurs semaines auparavant.
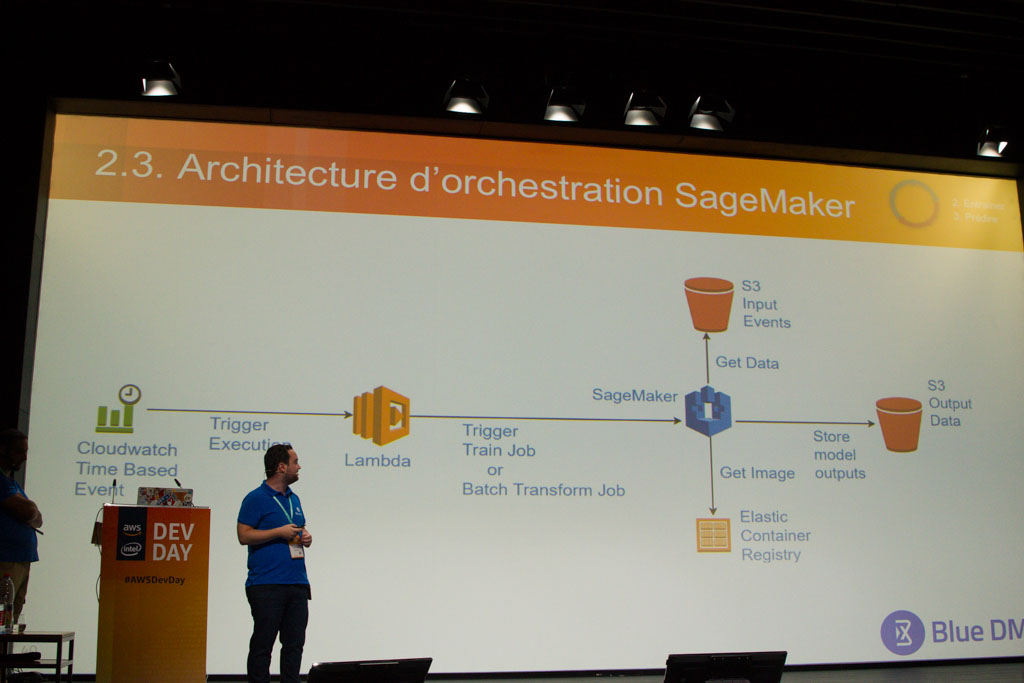
Afin d’aborder Sagemaker dans les meilleures conditions, Mohamed Ben Khemis conseille d’avoir déjà des données stockées sur S3, et au besoin d’utiliser AWS database migration service. Pour terminer ce retour d’expérience, il évoque les prochaines features que l’équipe Blue DME souhaite explorer : la prédiction par lot, l’AB testing, le monitoring des KPI business et métriques des modèles de datascience…
Des familles d’instances pour le Machine Learning
Pour compléter ce retour d’expérience, Julien Simon a cité l’exemple d’une société spécialisée dans les images satellite, et qui utilise le machine learning pour automatiser les traitements et extraire des informations de leur banque photo (plus de 100 Peta octets). Mais le machine learning permet aussi d’optimiser le stockage de ces images grâce à un modèle qui détermine le service de stockage le plus adapté à chaque image, une photo du milieu de l’océan étant a priori moins susceptible d’être consultée que celle d’une grande ville. Cette optimisation a permis de réduire le coût de stockage d’environ 50%.

Après tous ces services de haut niveau, cette keynote s’est terminée par un passage dans les couches les plus basses, au niveau des familles d’instances dédiées au calcul, et donc particulièrement adaptées au machine learning. Julien Simon a cité les instances C5 (Compute de 5ème génération, conçues pour avoir la plus forte puissance de calcul), ou leur variante avec les C5D (SSD de dernière génération). A noter que les C5 disposent de l’architecture Intel Skylake et permettent donc des jeux d’instructions 512 bits, avec+25% de performance par rapport aux C4. Enfin, Julien Simon a également recommandé les instances GPU, notamment pour le traitement de médias en grand volume : les instances P3, de 1 à 8 GPU dans la même box, soit un petaflop de performance! Une fois qu’on a choisi les instances, on peut utiliser un ensemble d’AMI pré installées de deep learning, avec toutes les librairies de Deep learning populaires, les environnements à jour, etc. Si le sujet vous intéresse, nous vous conseillons de visionner la keynote ci-dessous.

Commentaires :
A lire également sur le sujet :






