
Dans ta science : l’acculturation de la Data Science avec Defend Intelligence

A la croisée de plusieurs disciplines, la Data Science s’appuie sur des méthodes et des algorithmes pour tirer des informations et de la connaissances à partir de données structurées et non structurées. Encore inconnu il y a quelques années, les métiers de la Data Science et du Machine Learning évoluent très vite. Compétences, méthodes, outils… dans cette série d’entretiens, nous confrontons notre expérience à celle du marché, avec la participation de Data Scientists et ingénieurs Machine Learning externes à Devoteam Revolve.
Anis, alias Defend Intelligence sur YouTube, Twitch et Twitter est Lead Data Scientist dans le retail.
Après son diplôme d’ingénieur, il a commencé sa carrière à San Francisco comme ingénieur de recherche. Il est ensuite revenu en France, où il a commencé à travailler dans le conseil en tant que Data Scientist.
Anis a aujourd’hui cinq ans d’expérience dans le domaine et il est très actif sur les réseaux sociaux, où il contribue à la construction d’une communauté Data Science, et à la vulgarisation de sujets comme les données personnelles et l’IA, ou encore des tutos de code en Python.

Comment vois-tu le métier de Data Scientist ?
Pour moi le Data Scientist est entre l’enquêteur et le voyant. C’est un enquêteur parce qu’il doit vraiment comprendre les projets sur lesquels il travaille, et l’impact de la Data Science sur les métiers. En entreprise, on ne fait pas de la Data Science pour le plaisir, mais pour résoudre un problème. Cela paraît une évidence de lire, mais à l’heure où beaucoup d’entreprises ont encore du mal à délivrer des projets de Data Science et de Machine Learning, il faut comprendre ce qu’on fait, pourquoi on le fait et comment.
Par ailleurs, je ne considère pas le Data Scientist comme un développeur, parce qu’il n’a pas vraiment de cahier des charges précis quand il commence un projet. Il doit prédire X avec des données Y, mais il ne sait pas comment, il ne sait pas si l’approche choisie va fonctionner. Il y a une forte part d’incertitude qu’on ne retrouve pas chez les autres développeurs. Le code est un outil, mais on se sert avant tout de son cerveau et de sa capacité de réflexion et d’analyse.
Est-ce un travail comparable à celui de la recherche ?
En effet, on est plus dans la recherche appliquée. Je lis des papiers de recherche tous les jours, j’implémente des nouvelles approches en essayant d’appliquer des travaux issus de la recherche. Et parfois ça ne marche pas du tout !
C’est ce qui est intéressant, on peut découvrir une approche de recherche, essayer de l’appliquer à notre contexte, et bien que ce soit une approche qui ait prouvé son efficacité, ça ne marche pas. Les données d’une entreprise lui sont propres, deux entreprises du retail n’ont pas les mêmes données : les clients sont différents, les chiffres aussi, et les métiers ne vont pas chercher à maximiser la même métrique. C’est en cela que pour moi le Data Scientist n’est pas un développeur, parce qu’il n’y pas de méthodologie prête à appliquer. On peut avoir mené un projet chez un client, avoir un sujet proche chez un autre client et implémenter une solution complètement différente.
Quelles sont les compétences d’un Data Scientist ?
Quand je fais passer des entretiens, je regarde la capacité à produire du bon code. On pourrait même dire du “beau” code. C’est le problème de certaines formations de Data Science, on apprend aux étudiants à coder des des notebooks directement en Python, en oubliant toute la partie software engineering, la logique du code pur et dur. Résultat, les étudiants prennent des raccourcis, oublient comment définir une classe correctement, etc.
On regarde aussi la capacité à utiliser des outils mathématiques complexes. Il y a peu de temps, un DS junior m’a demandé pourquoi on utilisait un “loss”, parce qu’il n’avait pas fait la différence entre le MAE (minimum absolute error) et le RMSE (root mean-square error), et donc la différence entre une fonction absolue et une racine carrée.
Enfin, en termes de soft skills, et ça peut sembler évident, on attend du Data Scientist la capacité à être curieux. On vit une formidable époque pour faire de la Data Science, il y a des nouveautés toutes les semaines, donc il ne faut pas se reposer sur ses acquis. C’est un métier qui demande d’être proactif, il faut prendre les devants, ne pas attendre qu’on vous dise quoi faire, et mettre à jour ses connaissances très régulièrement.
Le Data Scientist est-il un plutôt un team player ou un ermite qui travaille seul ?
La réponse politiquement correcte serait le travail d’équipe, mais en réalité le Data Scientist peut travailler seul, en mode “blackbox” pendant un certain temps. Ce temps isolé lui permet de rentrer dans le sujet, de se poser les bonnes questions sans être interrompu régulièrement.
Ceci étant dit, le Data Scientist répond à des problématiques produit, et au sein d’une équipe produit. S’il peut faire le travail de veille et de modélisation seul, il ne peut pas, et ne doit pas, construire le produit seul. Or beaucoup d’entreprises demandent aux Data Scientists des tâches qui vont au-delà du modèle : monter un site internet de démo, administrer une base de données… Le Data Scientist ne devrait pas faire le travail du DevOps, du Data Engineer, du Data Analyste et le dashboarding en plus. C’est contre productif par rapport au travail au sein d’une équipe produit.
Quels sont les outils que tu utilises le plus souvent ?
J’utilise surtout PySpark et la librairie TensorFlow. Depuis deux ans, je ne fais quasiment que du Deep Learning, et je n’utilise plus de modèle de random forest ou de modèle classique de Data Science. Je crois beaucoup au deep learning, d’où l’usage de TensorFlow.
Est-ce que le Deep Learning est une approche facilement validée par les clients ?
C’est assez compliqué. Le plus gros challenge en entreprise, c’est l’acculturation data, pouvoir faire comprendre ce que l’on fait. Quand on présente des résultats, il faut pouvoir expliquer au métier la méthode, et comment on parvient à ces résultats. C’est dans cette optique que j’ai lancé une chaîne Youtube, pour m’entraîner au travail de vulgarisation.
Le Data Scientist doit pouvoir expliquer simplement son travail à des interlocuteurs qui ne savent pas ce qu’est une matrice ou un vecteur. Seulement, vulgariser c’est un peu transformer la vérité, simplifier, donc il faut trouver le juste milieu et pouvoir répondre à la curiosité des gens en fonction de leur niveau d’expertise. Avant chaque acculturation data, je pose quelques questions pour comprendre le niveau de l’audience, et adapter mon discours et le niveau de vulgarisation.
Et le Cloud ?
Le cloud est immensément important. Je n’ai plus besoin de démarrer Python sur mon ordinateur, je fais tout sur le Cloud, c’est un confort incroyable. Le cloud apporte beaucoup de puissance, même s’il reste encore du travail à faire du côté des éditeurs -voir la faille de sécurité récente sur le Cloud Microsoft. Dans le contexte du monde du travail qui évolue avec beaucoup plus de télétravail, pouvoir déporter la puissance de calcul de façon sereine, c’est essentiel.
Mettre en production des modèles de Machine Learning, c’est compliqué ?
Je crois que seules des entreprises comme Google et Facebook ont beaucoup de modèles en production. Pourquoi le passage en production est-il compliqué ? Au niveau organisationnel, historiquement, la production de code se fait au sein de la DSI. Or, si on met une équipe de Data Science dans la DSI, on tue l’innovation !
Une équipe de Data Science est faite pour driver la transformation numérique de l’entreprise, et c’est pour cette raison que de nombreuses entreprises la considèrent comme une équipe d’innovation, et la sortent de la DSI et de ses process. Il y a de fait une frontière qui se crée entre les équipes qui codent côté métier, et la DSI qui met en place des règles ne permettant pas des itérations rapides pour livrer des produits de Machine Learning à forte valeur ajoutée.
L’IA n’est pas un logiciel, on ne peut pas opérationnaliser des modèles de ML comme on le fait avec un site internet (voir schéma ci-dessous). On voit cette boucle d’itération et d’incertitude. La DSI n’aime pas l’incertitude, elle comprend mal qu’on puisse mettre en production sans savoir si ça va fonctionner. Et si ça marche, peut-être que le mois prochain le data set aura changé, et le modèle ne fonctionnera plus. Il y a donc un travail d’acculturation à mener auprès de la DSI, en plus du problème évoqué plus haut, à savoir qu’on forme les jeunes Data Scientists à livrer des notebooks, mais pas du code industrialisable.
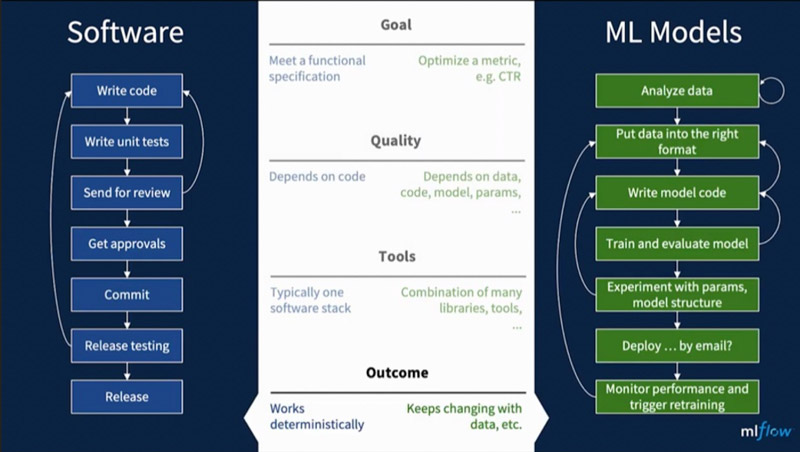
Est-ce que le ML Ops va permettre de mettre plus rapidement en production ?
Je ne suis pas sûr qu’on ira plus vite en production, mais on le fera mieux.
Avec le ML Ops les modèles vont vivre en production, exploiter des données de feedback, recalculer des métriques pour vérifier que le modèle fonctionne toujours, les boucles CI/CD mettront de nouvelles versions en production, etc. Le ML Ops va permettre d’allonger la durée de vie des modèles.
Quels sont les pain points au quotidien ?
Déconstruire les idées reçues ou les raccourcis qui circulent sur les réseaux sociaux ! Le métier les entend aussi , et tout cela contribue au mythe d’une IA magique, qui se construirait d’elle-même, et répondrait automatiquement à tous les problèmes. Il faut constamment déconstruire les idées reçues, c’est compliqué mais cela fait partie des challenges de notre métier.
Le mot de la fin ?
En France et en Europe, sur le sujet de l’IA, il faut arrêter de se poser des questions qui n’ont pas lieu d’être. Oui il faut être vigilant, mais pour autant ne pas freiner l’innovation par la réglementation. Les Etats-Unis, la Russie, la Chine avancent très vite sur l’IA. Nous, on se demande encore si l’IA est une menace pour l’humanité, alors que pour l’instant il n’y a que très peu de modèles en production dans un grand groupe qui ne détecte ne serait ce qu’un chat d’un chien. Il faut laisser les techs parler de ce qu’ils savent faire, et leur laisser prendre des places de management dans la data science, plutôt que de pousser des gens par politique, qui ne comprennent quasiment rien à comment marche vraiment l’IA concrètement, au delà de ce qu’on peut lire dans n’importe quel journal.
Enfin, notre travail demande de l’humilité : ce qu’on sait aujourd’hui ne sera peut-être plus vrai demain, donc il faut être bienveillant dans nos échanges. C’est de l’échange que naît la connaissance dans notre domaine, d’où l’importance du travail communautaire.
Retrouvez Anis sur YouTube :
Commentaires :
A lire également sur le sujet :





