
Sustainable AI: how can we reduce the carbon footprint of models?

AI brings solutions to many problems, but it also comes at the price of increased energy consumption.
In this article, we’ll take a look at existing, concrete and easy-to-implement techniques for making our AI models less energy-hungry, so as to limit their environmental impact. We address the three pillars of sustainable AI: monitoring, optimization and recycling.
This article is inspired by the conference « Reducing the carbon footprint of machine learning models » presented by Marc Palyart (Malt) at Dataquitaine 2023.
Monitoring
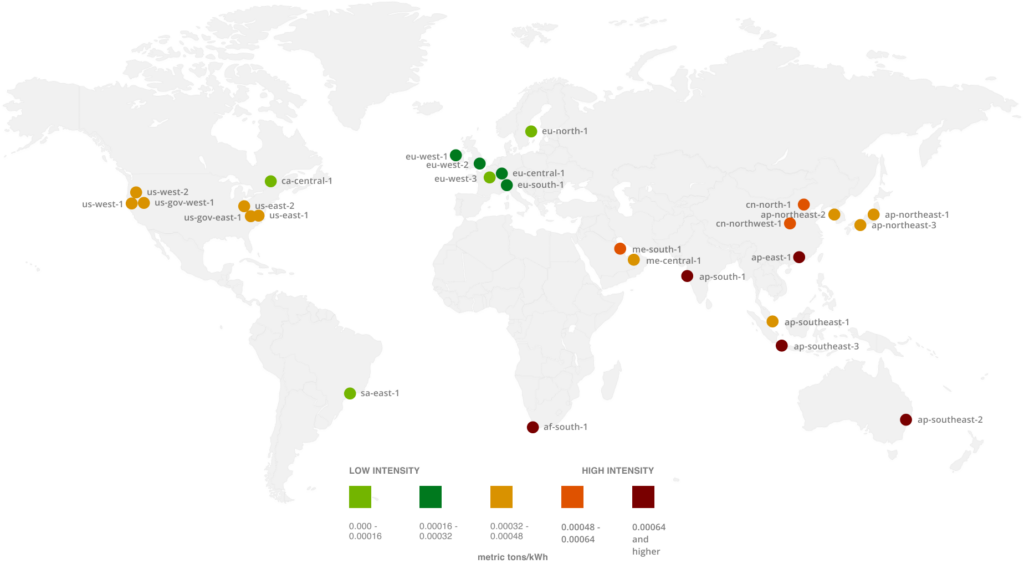
AWS region impact depending their energy mix
Measuring one’s impact in terms of carbon footprint is certainly the first thing to do. Even if the approach is sometimes based on a legal obligation, this quantification can be a source of awareness within the company. Monitoring will make it possible to measure the improvements that have been made, and the progress that still needs to be made. These measures can complement existing performance KPIs.
Here’s a short list of tools that make it easy to do so:
- https://codecarbon.io/: python package for integrating CO2 production tracking, or at least estimation, into code.
- https://github.com/lfwa/carbontracker: python package for carbon tracking of deep learning models.
- https://www.cloudcarbonfootprint.org/: dashboard application for tracking the CO2 production of your cloud infrastructure.
- Aws-customer-carbon-footprint-tool: service integrated directly into AWS. For the moment, the information provided is still limited. But it could be the first step towards more comprehensive tools.
The calculation is generally based on the resources consumed (CPU/GPU, RAM), the associated power consumption, and the datacenter’s energy mix. Although this is only an approximation, it enables us to identify the most important factors, and therefore to focus our efforts where they will have the greatest impact.
In the same way as it’s possible to keep these measurements in the infra monitoring section, it can also be interesting to integrate them into ML monitoring, which will help to raise awareness among data scientists (with MLFlow, for example). By placing model performance and associated power consumption side by side, we can begin to think not just in terms of effectiveness, but also in terms of efficiency.
Optimizing
Once the first estimates have been made, we can start optimizing the system. Here is a non-exhaustive list of the most commonly used optimization techniques.
- Allow yourself to design systems without AI
Indeed, this is the first Machine Learning rule established by Google: « Don’t be afraid to launch a product without machine learning » (Google, Machine Learning Rules). As it’s a trendy subject, there can be a tendency to put it all over the place, without it always being relevant. The author suggests that we should always leave ourselves the option of replacing predictive models with simple business rules, if they are sufficient to meet the need, or even abandon a project if the added value is not obvious.
- Use simple, resource-efficient models
In many cases, conventional ML algorithms deliver good results, so there’s no need to resort to deep learning. And even in the case of deep learning algorithms, not all are equal in terms of resource consumption. So it’s important to always compare predictive performance with energy performance, in cases where the added value is not obvious.
- Choosing datacenter locations based on their environmental impact
In some regions, access to green energy sources is easier/developed. They therefore have a better energy mix. Selecting a region based on these criteria can therefore also be part of your action plan. Beware, however, of data transfer, which also has an impact. It could prove counterproductive.
- Optimizing hyperparameter search
When optimizing hyperparameters, rather than systematically testing all possible combinations, it’s better to use a random search, or even better, a Bayesian search. Numerous libraries, such as Optuna, are available for this purpose. AWS SageMaker also offers a solution.
- Deploy batch processing
In many cases, real-time processing is not necessary, and can easily be replaced by batch processing. Real-time processing requires an endpoint that is always active in order to respond to requests. When a batch solution isn’t possible, there’s always the option of using serverless solutions, or intelligently managing application scaling.
- Use high-performance hardware
Hardware manufacturers are increasingly taking energy consumption aspects into account in the development of their products, in addition to computing performance. It can therefore be a good idea to keep a close eye on the new instances available, so as to be able to update your processing pipelines when a new processor or graphics card becomes available. For example, switching from a P4 (A100) to a P5 (H100) instance saves GPT-3 training time by a factor of x6 (up to x30 for LLMs), while power consumption has increased by a factor of 1.75 between the two versions. In terms of energy efficiency, this represents a gain of over x3
- Use the right hardware
To use the right hardware for the task in hand, you need to find the best compromise, such as a good memory/computing power ratio. Note that the best configuration for the training phase will often be different from that for inference. If there’s any doubt between several hardware solutions, why not run a benchmark to identify the best ones?
- Updating your libraries
In the same way, updating your libraries on a regular basis not only improves the security of your applications, but sometimes also enables you to benefit from the latest software optimizations. These will enable you to get the most out of your hardware.
Optimizing your models
The use of a model portability and/or optimization framework:
These include ONNX, the benchmark for deep learning model portability, TensorRT (Nvidia) and Openvino, which facilitate compilation for specific devices, and DeepSparse, which focuses on CPU execution. Treelite is another example of tree-based models, although the gains are less significant than for deep learning models.
These frameworks are generally used to deploy on edge infrastructures, with low-power devices, and with strong constraints in terms of power consumption. What is often overlooked, however, is the fact that it is also possible to use these optimization techniques in more traditional environments, such as in the cloud, in a context where resources are theoretically not so limited. On AWS, SageMaker Neo facilitates the compilation/optimization of models, whether for use on cloud instances, or in an edge computing context. This approach can be implemented fairly quickly, and without the need for special skills in this area.
A model compiled for the target device will generally be faster, taking up less memory space and CPU/GPU resources. Its smaller size will also make it easier to transfer over the network in the event of an update, as well as to store. The number of installed dependencies is also generally reduced.
To get a little more technical, here are some of the techniques used to optimize models:
- Quantization/Precision reduction
A technique specific to neural networks, which consists in reducing the number of bits used to represent the weights. This reduces the precision of the calculation from 32bits to 16bits, or even 8bits. This saves time during inference, and reduces memory requirements, computing power and energy consumption. The impact on performance in terms of prediction can be more or less significant. Quantization can be performed after or during training. Post-training quantization is more common and simpler, but tends to reduce predictive performance more than « quantization-aware training ».
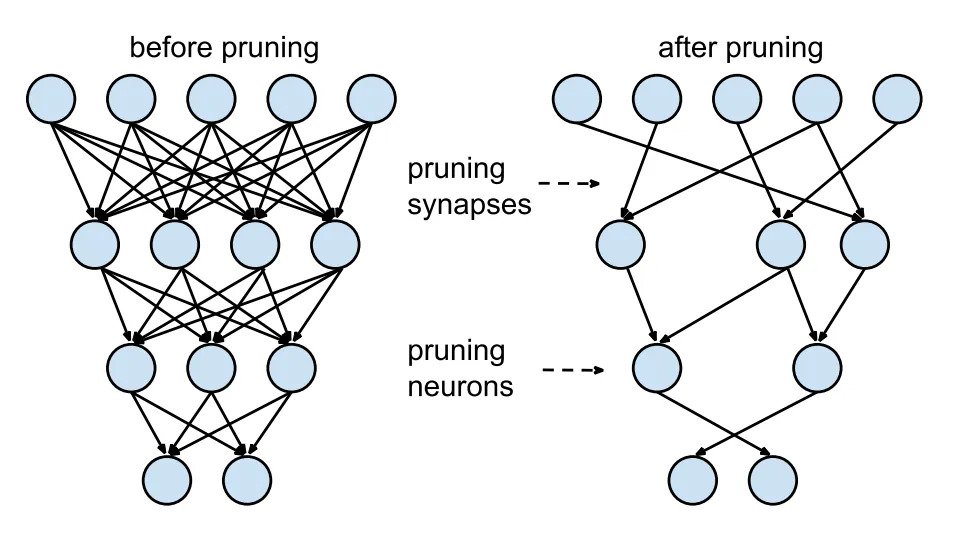
- Pruning
Optimization of the graph by deleting certain neurons or connections that have the least impact. Similarly for tree-based algorithms, it is possible to prune certain branches that have little impact on prediction.
- Optimzing hollow matrix calculations
Some libraries, such as Neural magic, optimize these calculations, so that algorithms can be run more efficiently on CPUs, to the point where GPUs can be dispensed with, thus reducing power consumption.
- Optimizing Python code
In the case of custom algorithms, it may be worth optimizing your Python code by using a library to compile the most resource-hungry parts. Numba, for example, enables you to do this quite quickly, by adding a decorator to the function of interest.
Recycling
In general, the reuse of models reduces training time, which in turn reduces energy consumption.
It can take many forms, of which the following are just a few.
- Intelligent re-training
Automatic re-training is often mentioned when discussing ML Ops. When it comes to dealing with potential data drifts, re-training often offers a simple to implement, and in most cases effective, solution. However, we mustn’t forget that these re-trainings will consume energy on a recurring basis. It’s therefore vital to design this part of the program so that models are re-trained only when really necessary, and not as a matter of course.
- Setting up caches
In the event of certain queries being repeated, a cache system for predictions will reduce the load on the inference endpoint.
- Fine tuning/transfer learning
The principle is to take a model that has been trained on a certain dataset, and re-train/adjust it to the target of interest. This greatly reduces the training time required. There are a plethora of « zoo models » offering this free of charge, such as Hugging face, Pytorch and Tensorflow, to name but the best-known.
- Zero shot/ Few shot learning
These terms cover a whole range of techniques for pushing back the limits of transfer learning. Thanks to new deep learning architectures, it is now possible to train high-performance models with very few examples. This means less annotation work for humans (with all the ethical considerations that this entails), and less energy consumed in fine-tuning. It’s important not to forget, however, that training the source model itself is often very energy-intensive. But their reusability more than makes up for this. It’s an initial energy investment that will increasingly pay for itself over time. A parallel can be drawn with the manufacture of a solar panel or a wind turbine.
- Distilling your models
This approach reduces the size of a model. And a smaller model means less computation, and therefore less power consumption. The principle is quite simple: we use the predictions of our starting model (teacher) as a training source for a smaller model (student). This distillation principle is often used on modern architectures. Interestingly, some hubs, such as Hugging face, offer models that have already been distilled. In this case, why not use them as replacements for the original models, for transfer learning for example?
As you can see, these techniques not only optimize energy consumption, but often also the speed of model inference.
As infrastructure costs are also reduced, it may be worth integrating this type of approach into a FinOps project. When financial interests are aligned with ecological interests, this can be a very effective lever.
Commentaires :
A lire également sur le sujet :






