
Le ML Ops – partie 3 : la définition d’un algorithme ML

Voici le troisième article de notre série consacrée au Machine Learning en production et ses solutions ML Ops dans le Cloud. Après une première partie d’introduction revenant sur l’évolution du métier de Data Scientist, l’historique du ML Ops et notre approche du ML Ops (à lire ici), une seconde partie sur l’intérêt d’une démarche de Machine Learning face aux approches de programmation traditionnelle (à lire ici), on plonge aujourd’hui au coeur du sujet : l’algorithme ! Avant de répondre à la question : pourquoi devriez-vous faire confiance aux prédictions des Data Scientists ?
Partie 1 : Le Machine Learning en production et ses solutions ML Ops dans le Cloud
Partie 2 : Pourquoi se lancer dans une démarche de Machine Learning
Partie 3 : La définition d’un algorithme ML
Partie 4 : Pour une stratégie de réutilisation des solutions
Définition d’un algorithme ML
Pour faire suite aux propos de l’article précédent, l’algorithme est donc la séquence d’instructions de cet exercice d’approximation d’un modèle “oracle” inconnu (un modèle théoriquement optimal: performant au point d’estimer sans risque d’erreur la réalité.). Et le modèle retenu est la solution empirique, la formule mathématique choisie parmi tant d’autres en raison de la sélection pertinente de ses variables caractéristiques (features), et de l’ajustement convenable de l’ensemble de ses paramètres.
La phase d’apprentissage est, dans des circonstances typiques, hors théorème de Gauss-Markov, une procédure itérative (par descente stochastique de gradient, le plus souvent) sur l’échantillon représentatif de données. La consigne étant d’itérer jusqu’à ce que la formule approximative permette d’atteindre un seuil de performance estimative satisfaisant.
Pour illustrer ces notions un brin complexes, voici un cas d’école : la régression linéaire (qui est la topologie la plus simpliste de la famille des réseaux de neurones).

Le but d’une régression linéaire est de modéliser la relation inhérente entre plusieurs coordonnées dans un plan, à des fins d’extrapolation.
- Dit familièrement, trouver dans le plan l’équation d’une droite affine qui projette au mieux l’ensemble des points. Comme dans un jeu de carnet de vacances, où un trait est à faire passer par des marquages, pour représenter un motif.
- Dit en termes mathématiques, approximer une variable observée, notée y. Avec une équation qui lie plusieurs caractéristiques xi , portant chacune une part d’explications sur le comportement de la variable cible. L’objectif est alors de déterminer le juste équilibre dans les poids qu’exercent chacune des variables explicatives à l’intérieur de l’équation :
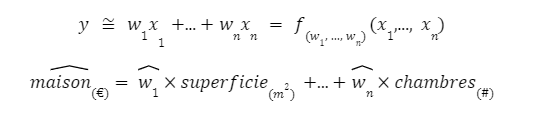
L’algorithme d’apprentissage statistique vient justement relever ce défi de déterminer les paramètres (wi)i=1,…,n les plus conciliables avec l’exercice de modélisation à résoudre.
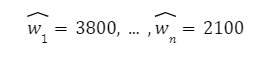
L’idée étant qu’une fois ces poids fixés, le modèle n’aura ensuite besoin que d’un lot d’observations (xi)i=1,…,n en entrée, pour offrir son estimation ŷ .
(Le symbole du « chapeau » en statistique est utilisé pour désigner tout terme qui est « estimé ». Par exemple, ŷ est utilisé pour désigner une variable de réponse estimée.)
Si les circonstances le permettent, l’algorithme peut être épaulé par un lot d’étiquettes (labels) qui lui communiquent les valeurs de la variable cible y, pour l’ensemble de l’échantillon représentatif. La tâche d’apprentissage est dans ce cas dite supervisée. À chaque tentative d’approximation, le modèle aura moyen de progresser, sachant quels ont été ses biais d’estimation = (y-ŷ) sur les itérations passées.
Aujourd’hui, pour un problème de modélisation par apprentissage statistique, une multitude d’approches peuvent être mises en concurrence. Trois critères majeurs permettent de chacune les différencier :
- la représentation : comment retranscrire par une fonction algébrique les connaissances acquises lors de l’apprentissage? Parmi les diverses familles d’algorithmes, voici les plus populaires : les arbres de décision, les réseaux neuronaux, les machines à vecteurs de support ou les modèles graphiques.
- l’évaluation : comment départager les approches candidates? Il est prépondérant (comme le laisse entendre la deuxième règle du machine learning) de retenir la bonne métrique d’évaluation pour l’exercice à entreprendre: selon s’il s’agit d’une classification, d’une régression, d’un clustering, etc. Citons quelques exemples : l’exactitude (accuracy), la précision ou le rappel, l’erreur quadratique moyenne, la courbe RoC, l’entropie.
- l’optimisation : grâce à quel processus de recherche converger vers les paramètres optimaux ? À choisir entre l’optimisation convexe, l’optimisation combinatoire, l’optimisation sous contrainte. Ou autres.
La mission de recherche et développement est alors de mettre au point une méthode d’apprentissage adéquate, en faisant la part belle parmi les approches potentielles. En vue de satisfaire la contrainte essentielle imposée à tout modèle ML, qui est de minimiser autant que possible le taux d’erreurs de généralisation (lorsque les données d’entrées présentent des caractéristiques inédites par rapport à celles ayant été observées dans l’échantillon d’apprentissage).
Disons que lorsqu’un modèle a été entraîné à distinguer un chat d’un chien, à partir d’images numériques où la représentation du chien est exclusivement incarnée par des labradors, alors le modèle fait preuve de robustesse s’il estime que l’image d’un chihuahua correspond bien à l’espèce canine. Il démontre alors qu’il est parvenu à induire certains éléments distinctifs entre ces deux espèces canine et féline (notamment au niveau de la forme du museau ou des oreilles).
À propos de cette contrainte, le fait que le contenu de l’échantillon représentatif soit abondant implique que les distributions des variables statistiques utilisées paraissent plus fidèles aux distributions observées dans la réalité terrain. Plus il y a de volume de data (ainsi que de variété et de véracité) pour étudier un signal, plus performant sera l’algorithme, vraisemblablement. Dans un effort de mise en contraste de l’information avec le bruit aléatoire capturé.
Ainsi, un numéricien aujourd’hui dispose de ressources à profusion (processeurs et données), qui faisaient cruellement défaut il y a quelques décennies.
Rappelons que la plupart des algorithmes ML ont été employés avec succès depuis au moins les années 1990 dans des applications commerciales. Mais cette pratique fut réservée pendant un temps à un cercle restreint de praticiens.
La mise en relation d’une quantité de données numériques en croissance exponentielle, depuis que le web nous a interconnectés, a en quelque sorte pavé la voie vers cette prodigieuse technologie qu’est l’intelligence artificielle 🤖 🧬. Tournant ainsi la page sur un épisode hivernal débuté fin des années 80 (l’IA ayant été victime de sa “hype”, déjà à plusieurs reprises).
Ce contexte favorable a alors créé en quelques années dans la décennie 2010 une dynamique où les grands noms de cette niche se sont mis, chacun leur tour, à vulgariser leurs connaissances au sujet des machines apprenantes. Au grand bonheur d’une communauté florissante de “data scientists en herbe”.
Jour après jour, le marché de l’emploi appelait en renfort ces novices en la matière, et Prof. Andrew Ng (pour ne citer que lui) a joué le rôle de parrain, en leur proposant le biberon des années durant, avec une certaine bienveillance.
Don’t worry about it if you don’t understand… ☺️
Andrew Ng – DeepLearning.ai
Une démarche scientifique
Bon, quoi qu’il en coûte, qu’attendre de ces scientifiques des données dans leurs interventions au quotidien ?
On peut, en tant que néophyte, vouloir rester en retrait de la méthodologie. Croire à leurs histoires fantaisistes, qui apportent par une formule magique le pouvoir de prédire votre prochain livre de chevet. Ou d’anticiper les risques hypothétiques de panne matérielle, de tentative de fraude, de défaut de paiement, etc.
Un scientifique des données passe effectivement ses journées à mettre au point des formules (de modèles). Mais contrairement à l’impression d’un tour de passe-passe, son activité est bien ancrée dans le monde de la pensée scientifique. Tous travaux, traités comme il se doit, se fondent sur des raisonnements mathématiques. Sur la maturation d’un concept par concertation avec des experts du domaine applicatif (subject matter experts). Et par analyse exploratoire de multiples sources de données.
La mise en action du savoir-faire d’un data scientist prend la tournure d’expériences visant à valider ou réfuter toutes sortes d’hypothèses statistiques. Sur un mode opératoire de recherche en laboratoire, et d’investigation sur le terrain. Avec un échantillonnage de données et un déroulement suivant une logique empirique.
Cela signifie que les résultats escomptés pour un modèle voulu ne sont pas toujours atteignables. La méthode d’organisation Agile est donc un bon compromis. Puisqu’il s’agit de déterminer rapidement si un cas d’usage au stade prototype peut déboucher sur un produit viable, dès lors qu’il serait exposé en environnement de production.
Le quotidien d’un data scientist est en somme relativement cyclique. Démarrer sur l’énoncé d’un problème métier à solutionner, récupérer un jeu de données de circonstance, évaluer diverses hypothèses, raffiner en rebouclant si nécessaire sur ses résultats, jusqu’à ce qu’un modèle pilote soit approuvé pour déploiement en environnement de production.
En poussant un peu la caricature, le quotidien du métier de data scientist est réductible à :
… → discussions avec les experts métier → essais (trials) → analyse → …
→ validation pour passage en production

source: jeremyjordan.me/ml-projects-guide
Qui plus est, un projet de modélisation ML avance en principe en rebroussant maintes fois chemin vers les étapes préparatoires de collecte et de traitement des données d’apprentissage, avant que la phase de déploiement du modèle ne soit effectivement franchie.
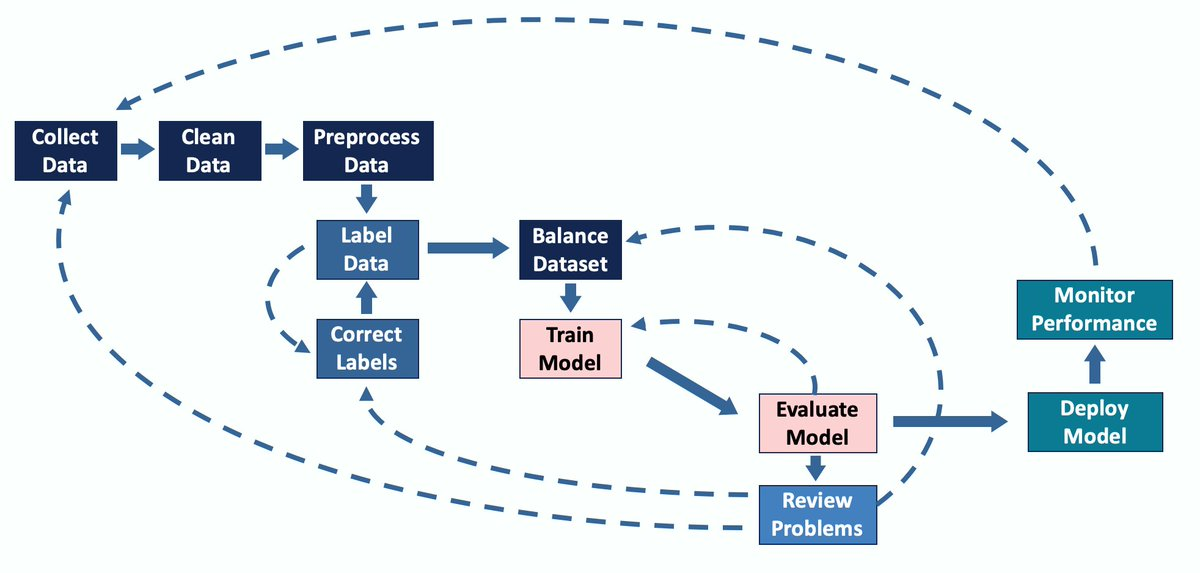
source: twitter.com/haltakov
Ce constat nous fait admettre qu’au terme d’une journée d’activité l’ensemble des rapports d’expérimentation sur tel ou tel projet applicatif est décidément à archiver, afin de conserver les connaissances acquises. Autrement dit, tout un lot de métadonnées est à indexer dans un système de stockage, pour s’y référer éventuellement par la suite.
Dans cet exercice de recherche d’un modèle assez satisfaisant, mieux vaut se rappeler de chaque différence d’approche, lors des boucles d’exploration et de raffinement successives. Il est préférable en effet de tracer tout changement, aussi minime qu’il soit, dans le paramétrage d’un algorithme ou dans l’approvisionnement en données d’apprentissage. Vu que ce changement à lui seul pourrait engendrer des gains (ou pertes) de performance conséquents sur le modèle résultant.
Prochain article : DevOps for ML – 101
Commentaires :
A lire également sur le sujet :






