
Hashicorp Vault upgrade: our entire Kubernetes cluster hit by a change in token review process

Today, let me talk about one of our most brilliant failure, hopefully, not in production.
Dog goes « woof »
Cat goes « meow »
Bird goes « tweet »
And everything fails
Story of a failed upgrade
The story starts a Monday morning. We had planned to deploy some boring changes to the « production like » environment, preparing the future deprecation of the 1.20 version of our Kubernetes cluster. In the changelog: some upgrades of Kubernetes add-ons, a few AWS configurations and the upgrade of our Vault cluster from the 1.7.0 version to the 1.11.1 version. These changes are not critical, but absolutely required to allow us to migrate to Kubernetes 1.22 in the next month.
The production-like environment is similar to our production, and is composed of:
- An Amazon EKS Kubernetes cluster running the applications of the company
- An Amazon EKS Kubernetes cluster running Hashicorp Vault and some CI/CD tools
As Hashicorp Vault was chosen to be the secret manager of the company, almost all Kubernetes pods require to get secrets from it at startup. It make this component one of the most critical components of the company. To mitigate the risk, and eliminate a potential deadlock problem, the Hashicorp Vault cluster runs on a dedicated Kubernetes cluster, isolated from the main applications cluster in another AWS account. This architecture allows us to run upgrades and node rotations on the EKS application cluster without the risk to take down the Hashicorp Vault cluster, and similarly, to run upgrades on the Hashicorp Vault Kubernetes cluster without impact on the applications already running on the other cluster because the secret retrieval is performed only at application startup.
Please take note of this two-cluster architecture, it will have a major impact in the next events of the day.
Having identified that Kubernetes JWT tokens will have their lifecycle reduced to « 1 hour » instead of « lifetime », an upgrade to an Hashicorp Vault version higher to 1.9.0 is required to have it supporting this new behavior. As Hashicorp Vault is designed for big versions jump, we were totally confident about the upgrade from 1.7.0 to 1.11.0.
Because we are cautious people, we also obviously had tested with success the upgrade of the Hashicorp Vault cluster on our sandbox environment. The sandbox environment has, for cost optimization reasons, only one Amazon EKS cluster running both the Hashicorp Vault cluster and tests applications using Vault. This difference between our sandbox installation and the production-like system is important to notice.
So, Monday morning, we applied all the changes to the Kubernetes cluster, and upgraded Hashicorp Vault to 1.11.0 in the production-like environment. Everything looked fine, and the day ended without a hitch. The next day, opening the monitoring dashboard on early Tuesday morning, we saw with horror that 1500 pods were down, falling to get their secrets with infinite loops of 403 errors.
This behavior of hundreds of applications crashing in the early morning was the combination of two facts: a lot of processes run early in the morning and, for cost optimization reasons, a lot of pods of the production-like environment are taken down during the night. It appeared then, that all the pods that had restarted after the upgrade had been stuck unable to log in to the Vault.
Facing a totally unexpected problem, we decided to rollback to Hashicorp Vault 1.7.0 to restore the production-like environment, and investigate the sandbox environment. The rollback performed in the production-like environment fixed the problem instantly.
What the hell was going on ?
The investigations were not easy. First of all, because our automated unit tests and integration tests have not seen any breaking change during the upgrade in the sandbox environment. Consequently, we had a pretty sure conviction that the problem is not reproducible in the specific sandbox environment and we had no idea how we could manage to see the problem without breaking again the production-like environment.
Reproducing the problem
Hopefully, because the team had dedicated its efforts the last few days to prepare a new Kubernetes 1.22 cluster, we actually had a fresh new isolated Kubernetes sandbox cluster called “green” containing only some test apps.The legacy « blue » sandbox cluster we used to run our tests with containing apps and vault. This architecture reproduces a two-cluster configuration as in production-like, and surprisingly, we managed to reproduce the failure with pods running on the « green » cluster and using the Vault on the “blue” one, while pods started directly on the « blue » cluster just ran fine.
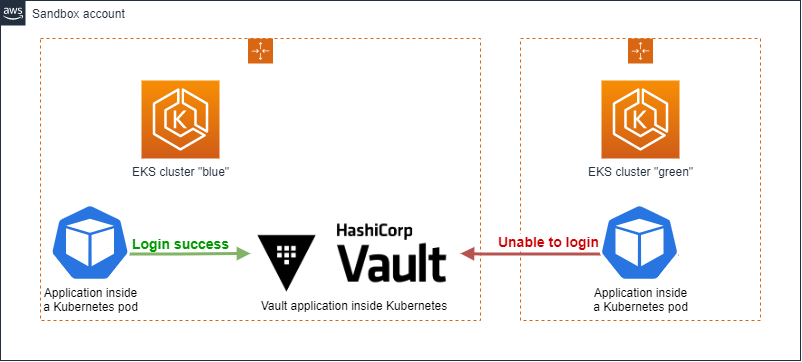
Having the problem reproduced in the sandbox environment, we believed to find the root cause quickly. It was not.
Into the logs
Our first move was to check in the Hashicorp Vault logs if anything interesting is written to it. We changed the log level to “TRACE”, restarted the Hashicorp Vault cluster and… Nothing more than the regular “403” logs when pods tried to authenticate. There was absolutely no clue about why the authentication failed, and the « TRACE » log level appeared to be really unhelpful to diagnose login issues.
Anonymized log below:
{"time":"2022-08-09T07:00:05.648356802Z","type":"response","auth":{"policy_results":{"allowed":true},"token_type":"default"},"request":{"id":"0221abae-xxxxxxxxxxxxxxxx","operation":"update","mount_type":"kubernetes","mount_accessor":"auth_kubernetes_763355aa","namespace":{"id":"root"},"path":"auth/eks-production-like/login","data":{"jwt":"hmac-sha256:xxxxx","role":"hmac-sha256:xxxxx"},"remote_address":"10.104.167.249","remote_port":33792},"response":{"mount_type":"kubernetes","mount_accessor":"auth_kubernetes_763355aa"},<strong>"error":"permission denied"</strong>}Assumptions
Then, we suspected a version incompatibility between the Hashicorp Vault agent executed in Kubernetes init containers and the Hashicorp Vault cluster, but it was again a false lead. Trying to upgrade the Vault agent version ended up producing the same results.
Well. We are engineers, and Hashicorp Vault developers are engineers too. There MUST be something inside the documentation we missed for the upgrade. Consciously, we read all the changelogs from 1.7.0 version to 1.11.0 to see if anything can be the root cause of the pod login failure. We found some notes about the deprecation of the parameters disable_iss_validation but flipping it did not change the behavior. There was absolutely nothing obvious in the changelog explaining why suddenly upgrading to 1.11.0 version can prevent our pods to register to the Hashicorp Vault cluster.
It was Wednesday afternoon, almost two days after the rollback performed on Tuesday morning and we were still stuck with absolutely no idea about what was going on. We spent the first day trying to reproduce the issue and since it is in front of our keyboards in the sandbox environment, none of the fixes we attempted during Wednesday morning worked. We finally realized that our investigations were maybe too focused on the Hashicorp Vault cluster. A big picture was missing: Hashicorp Vault rejects the authentication, but how does the authentication of a Kubernetes pods to a Hashicorp Vault cluster work? What is the workflow?
Into the Hashicorp Vault workflow for Kubernetes authentication
Hopefully there is in the Hashicorp Vault documentation great details about the Kubernetes authentication workflow.
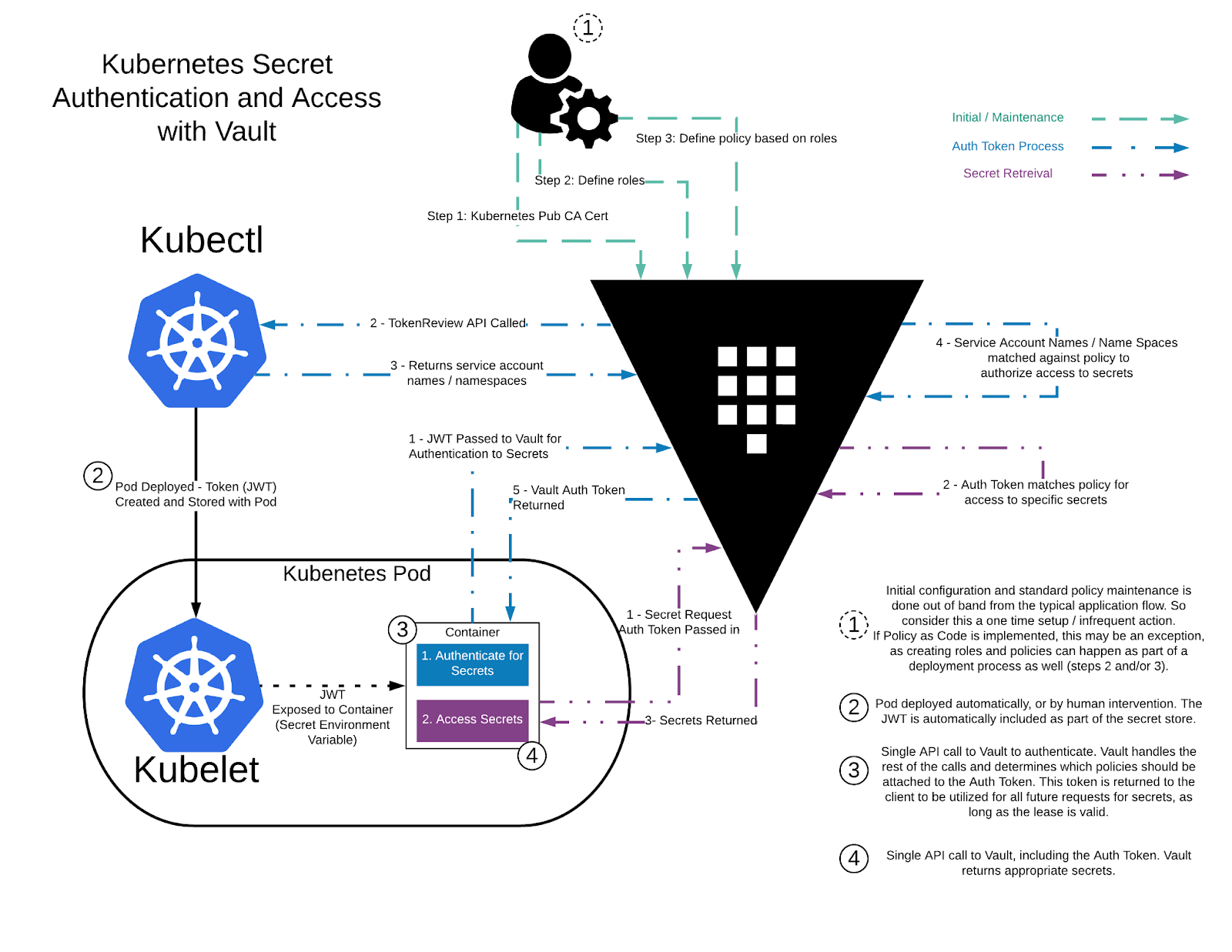
Image taken from https://learn.hashicorp.com/tutorials/vault/agent-kubernetes
The workflow is quite simple, lets focus on the auth token process:
- The Kubernetes pod take its JWT produced from Service Account and requests an authentication to the Hashicorp Vault cluster
- As administrators, we had initialized the Hashicorp Vault with an auth config containing the Kubernetes API server URL and certificate, consequently, Hashicorp Vault is able to know which TokenReview API it should use to check if this token is valid
- Once Hashicorp Vault have reviewed this token, validating it against the corresponding Kubernetes cluster (which with our use case, is not the cluster where currently Vault is located), it validates if the namespace of this token actually have access to Hashicorp Vault
- If everything passes, the pod is authenticated and an Hashicorp Vault token is returned. This token will be presented by the Hashicorp Vault Agent to the Hashicorp Vault cluster to get secrets.
Now that was easy. We just need to find where in this workflow things go wrong and we will have a more precise idea about what we can do to fix the issue. First, we validated that pods can collect a JWT token from service accounts, generating one manually. Then, we went through the Kubernetes logs looking for issues involving tokens and the TokenReview API and bingo, it appeared that the TokenReview API returns 401 errors:
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"xxxx","stage":"ResponseStarted","requestURI":"/apis/authentication.k8s.io/v1/tokenreviews","verb":"create","user":{},"sourceIPs":["10.89.23.190"],"userAgent":"Go-http-client/2.0","objectRef":{"resource":"tokenreviews","apiGroup":"authentication.k8s.io","apiVersion":"v1"},"responseStatus":{"metadata":{},<strong>"status":"Failure","reason":"Unauthorized","code":401</strong>},"requestReceivedTimestamp":"2022-08-10T14:05:58.301259Z","stageTimestamp":"2022-08-10T14:05:58.302575Z"}Root cause
Things were clear: the TokenReview API is a Kubernetes API, and thus, requires authentication prior to asking for it to review a JWT token. Unfortunately, for an unknown reason, Vault cannot authenticate to the Kubernetes TokenReview API, and then returns a “Permission denied” message to the pod.
Knowing that, lets check the configuration set up on our Hashicorp Vault cluster for Kubernetes authentication:
$ vault read auth/kubernetes-sandbox/config
Key Value
--- -----
disable_iss_validation false
issuer n/a
kubernetes_ca_cert -----BEGIN CERTIFICATE-----
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
-----END CERTIFICATE-----
kubernetes_host https://pod-apps-kubernetes-clusterThe configuration had not changed before upgrade, but something noticeable appeared: we had not configured an issuer. Consequently, there may be an issue here preventing the Hashicorp Vault process to authenticate through the Kubernetes TokenReview API.
We managed to set the token_review_issuer using the following commands, and all the pods instantly stopped receiving 403 errors and authenticated well. Below the script we used to set this parameter into the Hashicorp Vault configuration:
kubectl use-context blue-cluster
export SA_SECRET_NAME=$(kubectl -n vault get secrets --output=json | jq -r '.items[].metadata | select(.name|startswith("vault-sandbox-sa-token--")).name')
export SA_JWT_TOKEN=$(kubectl -n vault get secret vault-sandbox-sa-token-hx5sl --output 'go-template={{ .data.token }}' | base64 --decode)
export SA_CA_CRT=$(kubectl config view --raw --minify --flatten --output 'jsonpath={.clusters[].cluster.certificate-authority-data}' | base64 --decode)
export K8S_HOST=$(kubectl config view --raw --minify --flatten --output 'jsonpath={.clusters[].cluster.server}')
vault write auth/kubernetes-sandbox/config token_reviewer_jwt="$SA_JWT_TOKEN" kubernetes_host="$K8S_HOST" kubernetes_ca_cert="$SA_CA_CRT" disable_iss_validation="true"Why the hell did it work in the legacy « blue » sandbox environment ?
Reviewing the Kubernetes logs, we found something interesting. The JWT token used to call the TokenReview API was belonging to the Kubernetes cluster hosting Hashicorp Vault, and NOT the “applications” Kubernetes cluster configured in the Hashicorp Vault auth config.
All light on the TokenReview API, we managed to go through the life of a token extracted from a Kubernetes pod manually:
- We extracted an application pod’s JWT token
- We tried the pod’s JWT token against the Kubernetes host url configured in Hashicorp Vault, and it worked
- We tried the Hashicorp Vault local JWT token against the Kubernetes host url configured in Hashicorp Vault, and it failed as expected, because the Hashicorp Vault pods are not in the same Kubernetes cluster than the application pods
This explains why we did not manage to reproduce the problem with only one cluster. It appears that when token_reviewer_jwt is not set, the version 1.11.0 of Hashicorp Vault uses its local JWT token to authenticate through the Kubernetes API.
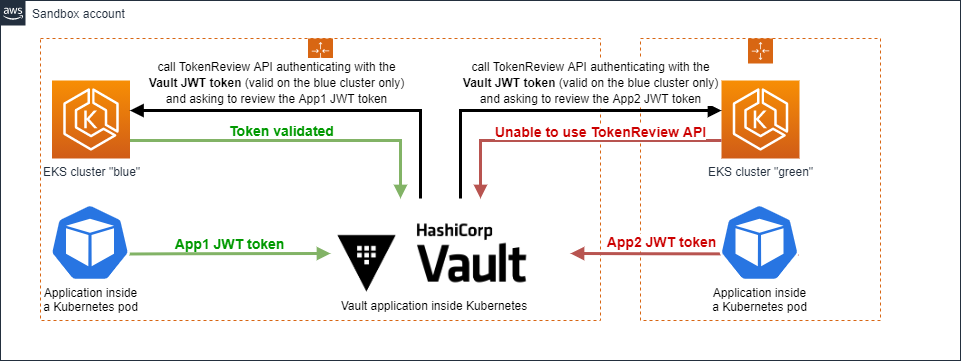
Understood. But it triggers another question: why did the 1.7.0 version work fine without the token_reviewer_jwt parameter ?
But why the hell did it work before the upgrade ?
This was the main remaining question of the Wednesday evening. If a long-living JWT token used to call the TokenReview API was (maybe?) always required, how the fuck the Hashicorp Vault cluster works when installed with the 1.7.0 version?
Our first thought was that a token was actually configured previously manually on the cluster, and the upgrade required setting it again. However, when the cluster was rollbacked to version 1.7.0, everything went well without any other action, excluding the hypothesis of an existing revoked token.
Browsing the documentation, we found this interesting table, talking about Kubernetes 1.21 token strategies. Indeed, starting Kubernetes 1.21, JWT tokens used by pods to authenticate to Kubernetes APIs will expire each hour.
| Option | All tokens are short-lived | Can revoke tokens early | Other considerations |
| (1) Use local token as reviewer JWT | Yes | Yes | Requires Vault (1.9.3+) to be deployed on the Kubernetes cluster |
| (2) Use client JWT as reviewer JWT | Yes | Yes | Operational overhead |
| (3) Use long-lived token as reviewer JWT | No | Yes | |
| (4) Use JWT auth instead | Yes | No |
During our investigations, we have set up a long-lived token as reviewer JWT, as in scenario (3) and it worked. However, that was not the previous setup. The setup after upgrade seems to be the scenario (1): use the local Hashicorp Vault token as reviewer JWT. Nevertheless, if it was the previous behavior, pods would not have been able to authenticate from another cluster. As we use Kubernetes auth and not an external JWT auth, the previous behavior must had been to use the client JWT as reviewer JWT (2) and if the 1.11.0 version of the cluster do not do that by default, it means that something changed in source code without a CHANGELOG notice.
Walking through the Hashicorp Vault source code (yes we have done that…), somebody noticed this really interesting change, preparing the Hashicorp Vault software to the Kubernetes token lifetime change: https://github.com/hashicorp/vault-plugin-auth-kubernetes/pull/122/files#diff-f7febf2126e4c13f0730b2d06b8a6d3bdcb748f6379770c478888c2e4ea1949eR157

This change adds the following behavior: “If no token_reviewer_jwt attribute is set in config, override the TokenReviewerJWT with the local ServiceAccount token. If ServiceAccount token cannot be retrieved, let the TokenReviewerJWT variable empty.”
This change has the following side effect: if you do not configure a token_reviewer_jwt parameter, Hashicorp Vault automatically falls back to the local Hashicorp Vault token (except if it cannot get it) and then… It fails in a two-cluster mode because the local Hashicorp Vault token does not belong to the target TokenReview API of the corresponding request : the originating pod is located in another cluster.
Previously, when no token_reviewer_jwt is set, there was no fallback to a local JWT token, and the client’s JWT token is automatically picked up, as we can see it there: https://github.com/hashicorp/vault-plugin-auth-kubernetes/blob/release/vault-1.7.x/token_review.go#L84

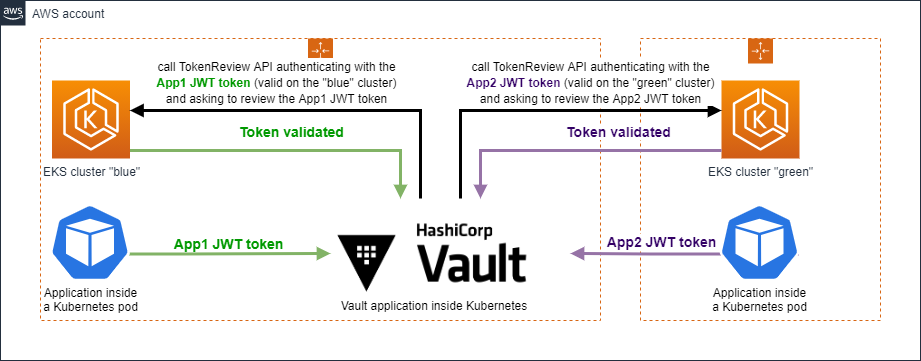
This new fallback behavior can be bypassed during migration by setting the DisableLocalCAJWT variable to True (using the disable_local_ca_jwt parameter) and actually… there is a documentation clearly explaining it in the recent versions of the documentation: https://www.vaultproject.io/docs/v1.11.x/auth/kubernetes#use-the-vault-client-s-jwt-as-the-reviewer-jwt
This process about how tokens are used to call the TokenReview API was not detailed in the 1.7.0 version of the documentation, and can explain why our ancestors never had documented this specificity in our deployment scripts: https://www.vaultproject.io/docs/v1.7.x/auth/kubernetes
It appeared that the disable_local_ca_jwt parameter was introduced in mid 2020. We can find some references of it in the CHANGELOG of the Hashicorp Vault Terraform provider: https://github.com/hashicorp/terraform-provider-vault/blob/main/CHANGELOG.md#2150-october-21-2020 and a modest note in the Hashicorp Vault changelog state “auth/kubernetes: Try reading the ca.crt and TokenReviewer JWT from the default service account [GH-83]”: https://github.com/hashicorp/vault/blob/main/CHANGELOG.md#150. This behavior is consequently quite old and not specific to Kubernetes 1.21, which was officially published in April 2021, although it was implemented to prepare for compatibility with the Kubernetes 1.21 clusters.
Our main mistake was to never go through the specific 1.21 documentation during the upgrade, because we were preparing the Vault upgrade on a 1.20 Kubernetes cluster. Actually, this setup with disable_local_ca_jwt applies to any Kubernetes versions, starting with Hashicorp Vault 1.9.0.
The Hashicorp Vault developers mistake is to have hidden this new parameter from their CHANGELOG. There is absolutely no reference about disable_local_ca_jwt in the official CHANGELOG and upgrade guides, preventing us to catch it early:
- https://github.com/hashicorp/vault/blob/main/CHANGELOG.md
- https://www.vaultproject.io/docs/upgrading/upgrade-to-1.8.x
- https://www.vaultproject.io/docs/upgrading/upgrade-to-1.9.x
- https://www.vaultproject.io/docs/upgrading/upgrade-to-1.10.x
- https://www.vaultproject.io/docs/upgrading/upgrade-to-1.11.x
Many details and source code to go through the token review process manually are described in this support article if you would like to go further: https://support.hashicorp.com/hc/en-us/articles/4404389946387-Kubernetes-auth-method-Permission-Denied-error
Conclusion
At the end, to make our Hashicorp Vault 1.11.0 upgrade work, we just set the parameter disable_local_ca_jwt to true and it worked as in 1.7.0 version. It was just that. This magic parameter has cost us many hours to be found (and many minutes to you reading this blog post).
Yes, we could certainly have found it more quickly, we may have had an ineffective debug process of our Hashicorp Vault, we could have looked at this documentation about the token review workflow more quickly. However, Hashicorp Vault is a complex software, and Kubernetes is a complex one too: debugging such a complex installation takes time. We have learned many enthusiastic elements from our Hashicorp Vault cluster and Kubernetes clusters during this story, and we now are more confident about their behavior and how we can react to failures.
Finally, I would like to take my hat off to all my amazing colleagues. We have spent almost two days together searching for the root cause of this madness, and none of us could have figured out all this shit without this collective debugging session. I am really thankful to have this team of brilliant people where everybody completes and supports others.
Commentaires :
A lire également sur le sujet :






