
Le ML Ops – partie 5 : la livraison continue, sauce ML

Cinquième article de notre série consacrée au Machine Learning en production et ses solutions ML Ops dans le Cloud :
- Partie 1 : Le Machine Learning en production et ses solutions ML Ops dans le Cloud
- Partie 2 : Pourquoi se lancer dans une démarche de Machine Learning
- Partie 3 : La définition d’un algorithme ML
- Partie 4 : Pour une stratégie de réutilisation des solutions
Comme mentionné dans le premier article, en réponse à cet impératif de stabilité dans l’écosystème de production, la communauté ML Ops opte pour une reprise du principe de livraison continue (continuous delivery), tel que défini à son origine :
La livraison continue est la capacité d’introduire des changements de tous types – y compris de nouvelles fonctionnalités, des mises à jour de configuration, des correctifs et des expérimentations – en production, ou entre les mains des utilisateurs, de manière sûre, rapide et dans une optique durable.
Jez Humble et Dave Farley
La chaîne de production…et ses contributeurs
Trois contributeurs du blog martinfowler.com (Danilo Sato, Arif Wider, Christoph Windheuser) reprennent en l’occurrence à leur compte ce sujet de chaîne de production d’une application de machine learning, dans leur article Continuous Delivery for Machine Learning (CD4ML). Ils y exposent leur vision de cette approche d’ingénierie logicielle, ramenée au contexte particulier ML Ops.
Le billet de blog revient sur le constat qu’un logiciel 2.0 peut évoluer de trois manières: par une modification de son code, de son modèle ou du flux de données ingérées.
Une application de ML a donc besoin pour son bon fonctionnement de faire coopérer les diverses parties prenantes : l’équipe gestionnaire des pipelines de données*, celle éditrice du code source et chargée de la livraison du modèle, et enfin celle gestionnaire de l’application qui embarque le modèle.
*Un pipeline de données est un processus d’extraction, de jointure et de transformation de données brutes, qui fonctionne sur la base de scripts de programmation et de schémas structurels d’objets. La séquence d’opérations qui y est décrite est donc versionnable et orchestrable automatiquement.
De nombreux témoignages ont maintenant rendu public le modus operandi des ténors du ML Ops. Et en résumé, la route vers l’archétype de maturité à atteindre passe expressément par la déconstruction des barrières organisationnelles qui divisent ces entités fonctionnelles. Toutes autant qu’elles sont, les entreprises de la Big Tech préconisent un cheminement vers l’automatisation. Vers l’orchestration automatisée de bout en bout du processus opérationnel en charge du cycle de vie du logiciel 2.0.
À ce titre, l’analogie entre cette conception ML Ops là et la philosophie DevOps fait maintenant sens. Vu que les principaux dogmes de la culture DevOps résonnent aussi dans les pratiques courantes de développement de logiciel 2.0 :
- Automatiser autant que possible les opérations → refouler toute prise d’initiative manuelle.
- Mettre un terme au comportement du « balancer par-dessus la clôture » → assumer la responsabilité d’un projet sur tout un cycle, de sa phase de conception, à celle de la maintenance en production.
- Accroître la vélocité et la qualité de la livraison des logiciels → adopter un état d’esprit de développeur pour les tests, le déploiement en production et les opérations : everything is code (toute action ou configuration est à instruire dans le format d’un script, suivant des bonnes pratiques d’ingénierie logiciel).
- Gouverner par la donnée → collecter et organiser le cheminement des flux de données au moyen de pipelines qu’un opérateur a possibilité d’instrumenter via un orchestrateur: everything is observable (toute trace d’activité majeure dans le système est à notifier dans un journal de bord, par mise en application d’une traque de métriques pertinentes).
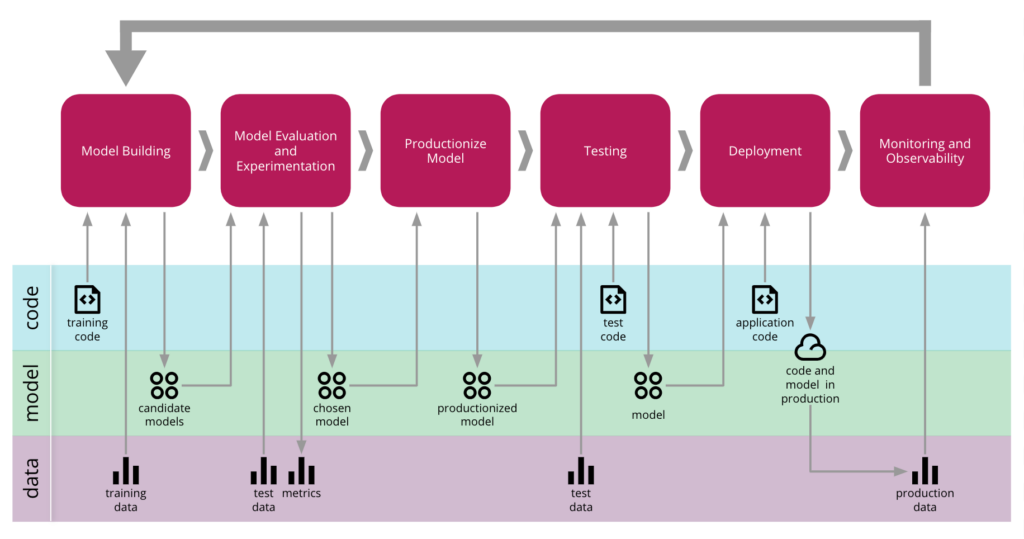
source: martinfowler.com/articles/cd4ml.html
Le pipeline ML
Ainsi soit-il. Au fil du temps, la culture DevOps a instillé le concept que le cycle de vie du logiciel 2.0 doit être géré au moyen d’un pipeline de formation de modèle de machine learning (training pipeline), qui comprend l’entraînement de modèles candidats, leurs évaluations, puis le déploiement en production de la version championne. Et enfin, la relance d’un nouveau cycle, lorsque le signal d’alarme est tiré par un agent observateur, humain ou machine.
L’un des atouts fondamentaux de ce design est que le pipeline ML a désormais la capacité de régénérer à la demande les sorties identiques à celles d’un cycle passé, si l’ensemble des dépendances en entrée est archivé et accessible.
Lorsque les data scientists en auront besoin, la plateforme ML Ops leur donnera ainsi moyen de restaurer une ancienne version d’un modèle ML, par reconstitution des conditions expérimentales dans lesquelles la formation se produisit à l’époque.
Par ailleurs, la livraison continue d’une application d’apprentissage machine (dans un contexte industriel à moyenne ou grande échelle) s’opère suivant une procédure en plusieurs étapes équivalente à celle employée dans l’édition logicielle 1.0 :
- l’intégration continue – des modifications du système consignables à tout moment.
- le déploiement continu – de nouvelles versions de logiciel déployables dans le système sans interruption de service.
La spécificité du développement logiciel basé sur un processus d’expérimentation statistique justifie l’ajout d’une boucle vue nulle par ailleurs, responsable de la création de l’objet ML :
- la boucle d’entraînement continu (continuous training) – une nouvelle tâche de formation de modèle prête à être exécutée sitôt le besoin exprimé.
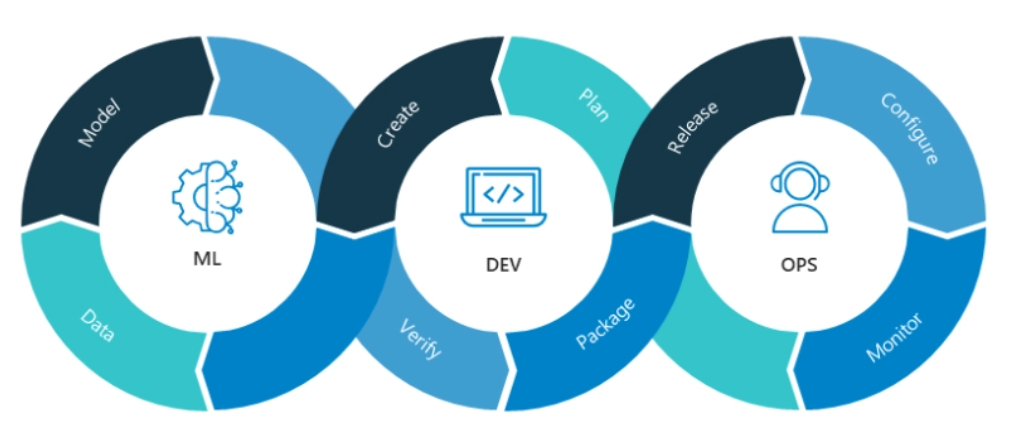
source: blogs.nvidia.com/blog/2020/09/03/what-is-mlops
La triple boucle infinie
Prenons le temps de parcourir le circuit que celles-ci forment ensemble : qu’est-ce qui est distinctement mis en œuvre dans chacune de ces boucles?
La boucle ML, l’entraînement continu
La boucle ML correspond à la gestion d’un pipeline d’entraînement continu. Ce pipeline est l’élément prééminent dans l’écosystème ML Ops. Au-delà d’un certain stade de maturité, l’objet à livrer par les data scientists n’est plus le modèle de machine learning, mais davantage le pipeline que l’on actionne sur commande pour opérer la tâche de formation d’un nouveau modèle plus à jour.
On pourrait ainsi, en empruntant la thématique de la production en usine, faire le parallèle entre ce pipeline et un organigramme de montage. Bien qu’en pratique, pour un opérateur, ce pipeline est plutôt admis comme étant un graphe orienté acyclique (DAG) qui pointe les unes vers les autres les tâches à traiter, selon l’ordre logique pour l’exécution. En vue de confectionner une solution prête à embarquer sur la chaîne de CI/CD.
Le flux de traitements CD4ML fait figurer ci-avant ce mécanisme d’entraînement continu dans ses étapes “model building”, “model evaluation and experimentation” et “productionize model”.
La structure du DAG sera plus ou moins complexe, selon le degré de généricité voulu. Voici une version basique du flux d’opérations à lancer en environnement de production (flux équivalent à celui employé en phase de prototypage, dit en passant) :
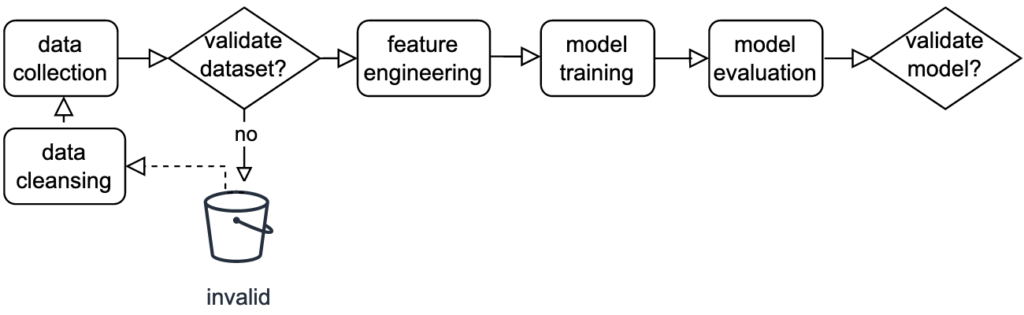
- La phase de collecte des données consiste à charger les sources d’information qui irriguent l’algorithme.
- L’étape de validation de la qualité des données consiste à apprécier la complétude et la cohérence de ces informations. Si des entrées irrecevables sont détectées, un assainissement des données (data cleansing) sera alors opéré en vue d’éliminer ou de rectifier ces observations erronées, synonymes de biais statistiques. À noter que le pipeline peut être conçu de sorte à ce que les cas invalides soient automatiquement signalés et consignés dans un compartiment de données distinctif, afin de forcer l’intervention d’un opérateur humain pour prendre en considération la nature de l’invalidité et rectifier manuellement la situation.
- La phase d’ingénierie du jeu de données d’apprentissage (feature engineering) consiste à rassembler les bonnes caractéristiques à fournir au modèle recherché, par transformation/minage du lot de données brutes. En s’appuyant sur les recommandations propres au domaine de connaissances métier. Ou en procédant à une étude de corrélation entre la variable à approximer et celles collectées, qui pourraient plus ou moins jouer un rôle dans l’explication du modèle suivant.
- La phase de formation consiste à livrer à l’algorithme d’apprentissage automatique un jeu de données d’entraînement ad hoc et un objectif d’optimisation à remplir. Dans l’attente de réceptionner un modèle capable de déduire passablement des cas de figure non exposés à ce stade.
- La phase d’évaluation du modèle consiste justement à challenger la capacité de généralisation du modèle, en l’interrogeant avec un jeu de données inédit, dit de validation. Cette séquence post-formation permet de déceler si le modèle a sous-ajusté (underfitting) ou sur-ajusté (overfitting) ses paramètres de pondération, compte-tenu des renseignements que l’échantillon d’entraînement lui a fourni. Cette procédure débouche en principe sur un rapport d’analyse de performance du modèle acquis, illustré par des indicateurs clés et des graphiques en tout genre.
- L’étape de validation des performances du modèle consiste à approuver ou rejeter la solution en sortie de pipeline. La décision (qui sera d’ordinaire actée par un opérateur humain) se base sur le rapport de performances qui lui sera présenté. Sur l’appui notamment d’un seuil de tolérance que le pouvoir prédictif de la solution doit atteindre à minima. Par exemple, dans le cadre d’un mécanisme de ré-entraînement automatique, ce seuil critique peut correspondre au score à battre du modèle précédemment mis en production. Ce dernier remet en jeu sa ceinture de champion, pour un affrontement supervisé avec des éléments d’arbitrage identiques entre les deux compétiteurs: même métrique d’évaluation, mêmes données de test.
Dans le cadre de la fabrication industrielle d’un modèle de machine learning (“productionize model”), la tactique de livraison continue 2.0 peut comporter en fin de boucle une tâche de ré-apprentissage du modèle. Oui, cette fois, avec l’accès à un jeu de données d’entraînement bien plus volumineux, puisé à même l’environnement de production. Et avec le recours à une infrastructure dédiée, dont les capacités de calcul sont nettement redimensionnées par rapport à la phase expérimentale : la complexité accrue des calculs matriciels à opérer étant à prendre en charge.
Cette tâche aura quoi qu’on en dise pour qualité de sonder plus en détails l’espace représenté par les relevés du terrain. Tout en se basant sur des hypothèses qui ont démontré leur validité sur un échantillon de taille réduite. Les data scientists ont des raisons de penser que le jeu de relance de la formation du modèle en vaut la chandelle, puisque leur préoccupation est d’obtenir des poids résultant d’une convergence la plus poussée possible vers l’optimum global de la fonction de perte. Et plus de données d’entraînement font que les distributions statistiques empiriques (celles exprimées par les données du terrain) reflètent plus fidèlement la loi de distribution statistique suivie en théorie.
Par ailleurs, autre point de bascule entre les environnements de prototypage et de production : pour des questions de latence ou de compatibilité, le choix du langage de programmation diffère parfois. D’une part, les data scientists ont tendance à privilégier Python, lorsqu’il leur est demandé de livrer la preuve de concept d’un modèle ML. Et d’autre part, certains ingénieurs, lors de la procédure d’industrialisation, préfèreront prendre le temps de traduire en Java/Scala ou C++/# le code du pipeline ML, afin que le dispositif opérationnel qui leur est confié se greffe de façon pérenne à la data stack existante (dans un contexte où les traitements de flux de données doivent techniquement supporter une forte intensité).
Training pipeline et serving pipeline
Qui plus est, l’idée de faire appel à un modèle ML en production soulève le besoin d’un pipeline d’inférence (serving pipeline).
Comprendre que le dispositif ML Ops compte non pas un mais deux pipelines est capital.
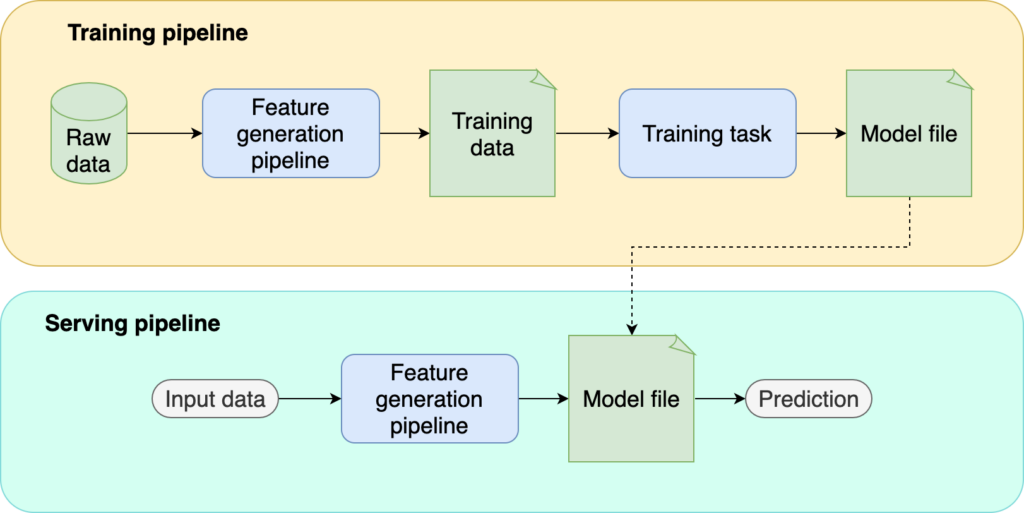
source: ploomber.io/blog/ml-testing-i
En fin d’apprentissage (au terme de l’évaluation de l’estimateur sur un jeu de données inédites), les paramètres du modèle (les poids du modèle) sont bien entendu à garder précieusement. Le pipeline de formation (training pipeline) se conclut donc par une action consistant à les écrire dans un fichier de configuration, lequel est ensuite enregistré dans une mémoire non volatile.
Le pipeline d’inférence a alors pour rôle de faire tourner un service.
Dès lors que l’artefact de l’estimateur est à notre portée (en récupérant les paramètres archivés), ce second pipeline ne demande qu’à être alimenté par des flux de données brutes. Néanmoins, avant que l’estimateur soit sollicité, l’ensemble des données acheminées doit d’abord être transformé en variables caractéristiques, par une tâche préliminaire d’ingénierie ML.
Par souci de consistance, soulignons le, la tâche de prétraitement mentionnée ici devra être la réplique à l’identique du processus de génération de features mis en oeuvre dans le pipeline de formation.
Par ailleurs, ce pipeline de service est à ranger dans la catégorie des logiciels 1.0 : il ne fera qu’adresser des requêtes au modèle ML, qui d’ordinaire à ce stade est exposé tel une boule de cristal, via une route API /predict.
La boucle DEV, l’intégration continue
La boucle ML est une fabrique à estimateur, par apprentissage automatique, d’accord.
La boucle DEV, elle, correspond au principe DevOps de l’intégration continue, qui est de mettre en place une gamme de tests. De sorte à éprouver sous tous les angles chaque nouvelle contribution individuelle (commit) au sein du projet d’édition logicielle.
Reprenons la thématique de l’usine: voyons la chaîne CI comme le processus qui opère le conditionnement et le contrôle du trafic sur la chaîne de livraison continue, en vue d’emballer ou de stopper (aussitôt que possible) tout envoi de colis défectueux en direction des étalages d’une boutique.
Le flux de traitements CD4ML fait figurer ci-avant cette étape de contrôle qualité dans son étape “testing”.
Garder à l’esprit que chacun de ces tests (du plus minime au plus exhaustif) apporte une brique à l’édifice de mise en conformité continue (continuous compliance) : une conformité en adéquation avec les spécifications fonctionnelles communiquées et attendues en sortie de l’application par le gestionnaire de produit (product manager). En accord avec les préconisations transmises par les représentants RSSI et DPO.
Le but de cet édifice de tests est avant tout de garantir le risque minime de régression de la solution auprès de la clientèle.
Posons nous la question. Quelles raisons pousseraient les opérateurs à approuver une nouvelle variante d’un logiciel 2.0 ?
- D’abord, s’il y a constat (découlant d’expérimentations menées par des data scientists) d’un affinement possible de la marge d’erreurs du modèle de machine learning,
- Ou accessoirement, s’il y a besoin d’une mise à jour des fonctionnalités du service applicatif (une évolution touchant à l’interface utilisateur, par exemple).
En soi, tout développement qui concerne l’écosystème MLOps touche :
- soit au niveau du pipeline ML (script de programmation de l’entraînement, fichiers de configuration de l’algorithme, etc.),
- soit au niveau d’un script d’une partie tierce de l’application (le pipeline client du service de prédiction, l’interface REST du service de prédiction, etc.),
- soit au niveau apparent des sources de données alimentant l’application (modification du schéma d’une table de données brutes, rafraîchissement du jeu d’entraînement, etc.).
Une procédure CI de “build & test” doit alors s’enclencher automatiquement dès notification qu’un différentiel demande à être inscrit sur le tronc de l’arbre de versionnement Git. Pour rappel, cet arbre Git est un support d’archivage des innombrables itérations touchant aux composants du logiciel. On lui crée un dépôt dédié (repository) sur un serveur central distant (remote server), hébergé sur un site tel que GitHub, GitLab, Bitbucket.
La chaîne CI s’arrête en théorie à l’action de sauvegarde du lot de commits qui vient d’être approuvé. La plupart du temps, l’équipe de développeurs opte pour la démarche du Git flow :
- La variante est entreposée dans un premier temps sur une branche caractéristique éphémère de l’arbre Git (feature branch).
- Une demande de fusion (merge request) permet, au moment jugé opportun, d’intégrer le lot de commits sur l’une des branches permanentes: c’est-à-dire, selon l’état d’avancement, soit sur develop (environnement de travail expérimental), soit sur release (branche dédiée aux livraisons à l’environnement de production).
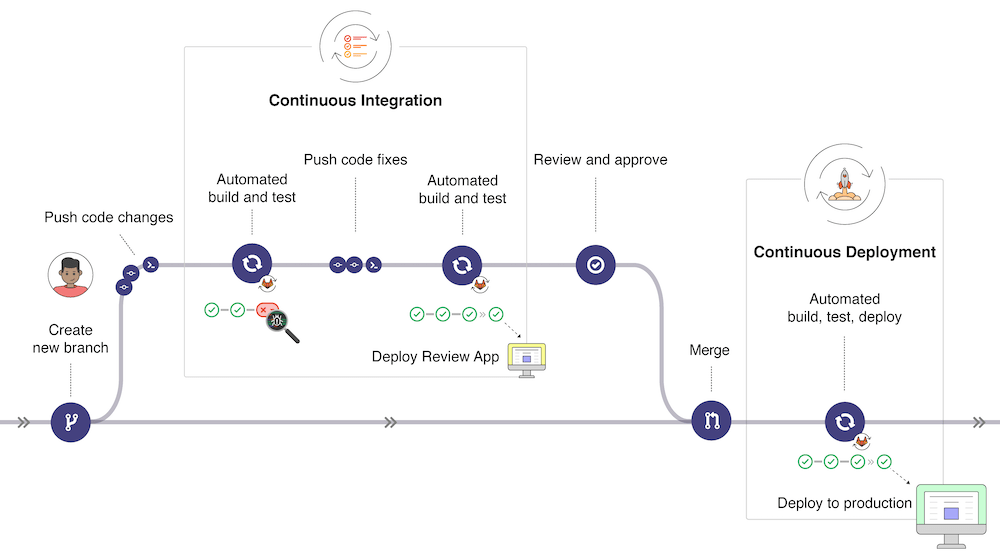
source: docs.gitlab.com/ee/ci/introduction
Aussi, ajoutons que la logique de livraison continue (continuous delivery) n’aboutit pas exactement à cette opération de fusion. Sa finalité est la mise en paquet (packaging) des artefacts générés en utilisant la version actualisée du logiciel.
Une mise en paquet donc, à laquelle est jointe en bout de course l’action capitale d’archivage (storage). Le paquet est déposé dans une boutique, qui servira par la suite de relais pour distribuer à la demande des lots d’artefacts, à tout type d’opérateurs.
Avec un pipeline de formation de modèle ML, voici comment mettre à exécution un plan de livraison continue, en adoptant ce processus de demande de fusion (comprenant des tests et une étape d’approbation) :
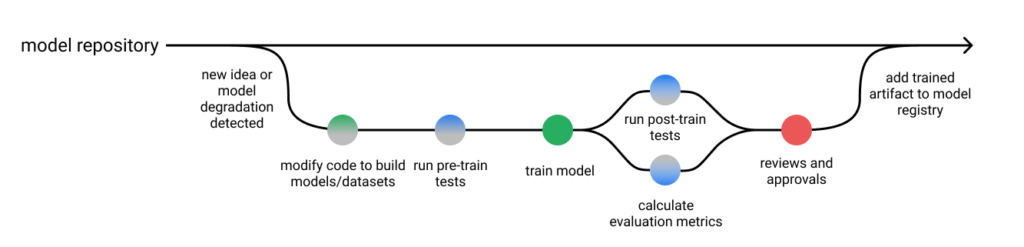
source: jeremyjordan.me/testing-ml
Côté gestion opérationnelle, il sera par ailleurs sans doute question, à un moment ou l’autre, de faire un choix dans la liste des outils spécialisés en intégration continue (GitLab-CI, Jenkins, GitHub Actions, etc.). Afin d’orchestrer dans de bonnes conditions la charge de travail de la chaîne CI/CD: car les bonnes pratiques DevOps nous conseillent d’exécuter la procédure d’intégration dans un conteneur virtuel (runner). Il est dans ce cas préférable de déléguer à un agent machine la responsabilité de cette mécanique d’ordonnancement et de gestion des erreurs.
À présent, ici, au sujet de la livraison continue d’un logiciel 2.0, abordons la question parmi les plus centrales. Que retenir dans la composition du paquet que l’on compte mettre à disposition des opérateurs du service (en fin d’un circuit qui fait transiter la marchandise du pipeline ML sur la chaîne CI) ?
Cette question nous amène à dresser un bilan de ce qui importe (pour les casquettes data scientist et opérateur) dans les résultats d’une expérimentation ML :
- quelle problématique fut à résoudre lors de cette tâche d’apprentissage,
- sur quels jeux de données l’expérimentation fut-elle menée,
- où sont maintenant entreposés les artefacts résultants,
- comment furent configurées les ressources infrastructurelles utilisées,
- si plusieurs essais d’hyper-paramétrage algorithmique furent mises en concurrence, lors de l’expérimentation:
- quel hyper-paramétrage fut choisi pour chacun des essais lancés,
- comment chacun des modèles se comporta dans la compétition,
- quel modèle fut élu champion.
A fortiori, mieux vaut conserver les éléments que nous venons de qualifier d’essentiels. C’est-à-dire :
- le projet logiciel (scripts et graphe d’orchestration du pipeline de formation),
- les configurations matérielles de l’instance de calculs (CPU, GPU, RAM, etc.),
- le modèle champion (l’algorithme, ses paramètres et hyperparamètres gagnants, en fin de processus de formation),
- les jeux de données d’apprentissage (un premier pour l’entraînement, un deuxième pour l’évaluation des performances, un troisième pour les tests supplémentaires),
- les métriques capturées tout du long de l’expérimentation dont est sorti le modèle champion.
Restons en là pour l’instant, puisque cette réponse sera davantage détaillée dans un prochain article : « Full-stack ML-Ops ».
Et du reste, lors des étapes “build” et “test”, constitutives de la chaîne CI, quels rouages ML Ops actionner ?
- Pour l’étape “build”, le dispositif correspond le plus souvent à une action classique de compilation, de compression ou de sérialisation.
- Pour l’étape “test”, le sujet a assez de matière pour s’étendre sur un article entier. Réservons nous le prochain paragraphe, afin de forger ensemble une opinion sur ce qu’est une bonne stratégie de tests MLOps.
La boucle OPS, le déploiement et l’observation continue des performances
La boucle OPS, la dernière des trois, gère quant à elle tout ce qui touche au socle infrastructurel du service applicatif. Le flux de traitements CD4ML fait figurer ci-avant ces champs d’action dans ses étapes “deployment” et “monitoring”.
Les tâches élémentaires de cette boucle sont :
- le provisionnement en ressources matérielles informatiques, au moment d’un déploiement logiciel (car oui, quelque part ici ou là, une machine physique est réquisitionnée pour servir l’application. Que cet instrument électronique soit entre vos mains ou au-dessus de nos têtes, dans le Cloud),
- les tâches d’observabilité (continuous monitoring).
Le monitoring vous indique si un système fonctionne bien.
Baron Schwartz
L’observabilité vous permet de saisir pourquoi le système ne répond pas aux attentes.
- les quelques ajustements nécessaires de la plateforme → un environnement de travail moderne implique d’avoir auprès de soi des opérateurs avec expertises:
- en système infrastructurel ouvert à de multiple et divers profils utilisateurs (SysOps),
- en cybersécurité (SecOps),
- en ingénierie Cloud focalisée sur l’optimisation des coûts (FinOps).
Enfin nous y voilà, à aborder la fin du cycle de vie d’un logiciel 2.0. Nous avons pris le temps d’évoquer le fonctionnement général de la chaîne CI, et de la logique de livraison continue.
Dans le fond, le pipeline de déploiement continu (continuous deployment) correspond au procédé qui va un cran plus loin que la livraison continue: ce cran extrême est le (re-)déploiement automatique des ressources logicielles dans le serveur qui héberge l’application.
À chaque constat qu’une intégration a réussi dans l’une des branches Git associées à un environnement de travail (develop, staging, production), le pipeline CD va enclencher une routine d’installation des versions de paquets les plus à jour (tag:latest) au sein de l’infrastructure cible (correspondant en pratique à un environnement isolé à l’intérieur d’une machine virtuelle).
Là où effectivement la livraison continue se contente d’offrir aux opérateurs la latitude de venir se servir eux-même dans le registre d’artefacts. Tout déploiement étant à actionner manuellement, par leurs propres soins.
Le déploiement en mode manuel présente à vrai dire un intérêt:
- s’il est question de lancer un processus de test A/B (en déployant par le mode canari, canary release, ou fantôme, shadow deployment).
- Ou si l’organisation en place choisit d’effectuer des livraisons groupées à intervalle régulier (à fréquence bi-mensuelle par exemple, alignée sur chaque fin de sprint Agile).
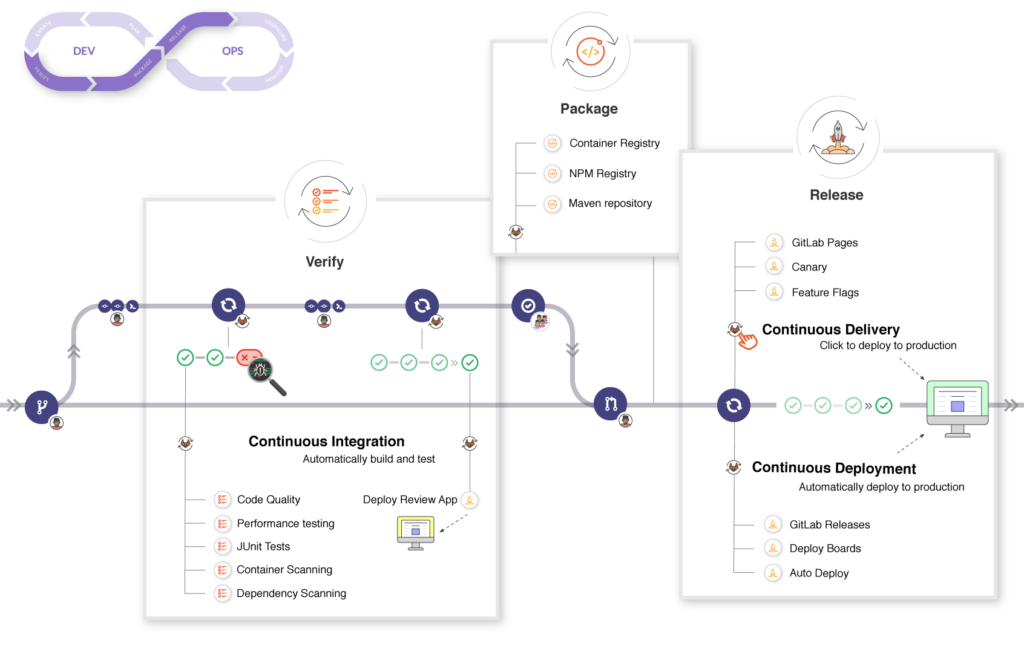
source: docs.gitlab.com/ee/ci/introduction
Dans le cadre MLOps, certaines étapes critiques requièrent de fait l’approbation d’un acteur humain, afin d’éviter un enlisement en production. Ce sera le cas notamment au moment de prendre position pour le remplacement du modèle ML d’exposition par une version outsider.
Avant toute mise en production, il est alors systématiquement recommandé de procéder d’abord à des tests A/B, ou des déploiements fantômes, en attendant de disposer d’une analyse comparative des performances suffisamment argumentée prouvant les qualités supérieures du modèle challenger en face à face avec le champion.
Pour clore ce (long…) sous-chapitre, rappelons en quelques mots que le concept de pipeline Continuous Training / Continuous Integration / Continuous Deployment / Continuous Monitoring est à mettre en place en réponse au besoin de réguler avec coordination tout événement susceptible de faire évoluer (en bien ou en mal) l’offre du service.
La chaîne de livraison doit recevoir les instructions pour faire tourner de son propre chef la mécanique de (commit >) build, test, store, provide infrastructure, deploy, observe.

source : martinfowler.com/articles/practical-test-pyramid.html
Prochain article : des tests, des tests, des tests, et du monitoring
Commentaires :
A lire également sur le sujet :






